OpenCV-Part2
OpenCV-Part2——图像处理(上)
[TOC]
HSV色彩空间
RGB与HSV格式转换
cv2.cvtColor(img, cv2.COLOR_BGR2HSV):将BGR图片转换成HSV格式。cv2.inRange(img_hsv, lower, upper):提取范围内的区域。- HSV图像的每个像素
[h, w]按[H, S, V]顺序存储。其中,H范围[0, 179]、S范围[0, 255]、V范围[0, 255]。 - 在对像素值标量进行表达式计算时,要将类型从
numpy.uint8转int,防止越界。 - 在针对提取某一种颜色之前,可以通过高通滤波来锐化边缘,提高对颜色较淡区域的捕捉能力。
1 | # 提取红色区域 |
找到要追踪的HSV值
- 使用相同的函数
cv2.cvtColor()传递期望的BGR值,而不是传递图像。
1 | # 查找绿色的HSV值, |
图像几何变换
缩放
cv2.resize():调整图像的大小。图像的大小可以手动指定,也可以指定缩放比例。出于调整大小的目的,默认使用的插值方法为cv2.INTER_LINEAR。dsize:shape是[高, 宽],dsize是(宽, 高)。fx/fy:缩放比例。
1 | img = cv2.imread("test.jpg") |
平移
cv2.warpAffine():dsize:输出图像的大小,其形式为(width,height)。记住width=列数/宽,height=行数/高。
- 将变换矩阵放入
np.float32类型的Numpy数组中,并传递给cv2.warpAffine函数。
1 | # 偏移(100, 50) |
![]()
旋转
cv2.getRotationMatrix2D(center, angle, scale):获取旋转矩阵。center:旋转中心(x, y)。angle:逆时针旋转角度,可以为负数。scale:以center为中心的缩放比例。
1 | img = cv2.imread("test.jpg") |
- 在如上的方法中,在非正方形的图中旋转,很有可能会受到画布大小的限制。
- 对于90°旋转可以使用
np.rot90函数。
1 | img_ = np.rot90(img) |
翻转
cv2.flip(scr, flipCode):上下/左右翻转图像。flipCode:1为水平翻转,0位垂直翻转
1 | img = cv2.flip(img, flipCode=1) |
变换
- OpenCV提供了两个转换函数
cv2.warpAffine和cv2.warpPerspective。 cv2.warpAffine采用2x3转换矩阵,而cv2.warpPerspective采用3x3转换矩阵作为输入。
仿射变换
- 在仿射变换中,原始图像中的所有平行线在输出图像中仍将平行。
- 通过输入图像中的三个点及其在输出图像中的对应位置,使用
cv2.getAffineTransform创建相应的变换矩阵,该矩阵将传递给cv2.warpAffine。
1 | img = cv2.imread("test.jpg") |

透视变换
- 对于透视变换,在转换后,直线也将保持直线。要找到此变换矩阵,需要在输入图像上的4个点,以及在输出图像上对应的4个点。在这4个点中,其中3个不应共线。
- 可以通过
cv2.getPerspectiveTransform找到该3x3变换矩阵,应用于cv2.warpPerspective。 - 注意,这里应用的是3x3变换矩阵,与2x2变换矩阵的方法是不一样的。
1 | img = cv2.imread("test.jpg") |

图像二值化
简单阈值
cv2.threshold(src, thresh, maxval, type):对于每个像素,应用同一阈值,用于对像素值进行分类。cv2.THRESH_BINARY:对于设定的thresh,小于则将当前像素值设置为 0(黑色),超过则将像素值设置为maxval(白色)。cv2.THRESH_BINARY_INV:与THRESH_BINARY互为翻转,可以用这一type省去手动翻转的过程。cv2.THRESH_TRUNC:对于设定的thresh,小于则将当前像素值*2,超过则将像素值设置为maxval(白色)。cv2.THRESH_TOZERO:对于设定的thresh,小于则将当前像素值设置为 0(黑色),超过则像素值不变。cv2.THRESH_TOZERO_INV:对于设定的thresh,小于则将当前像素值*2,超过则将像素值设置为 0(黑色)。
输入图像应该是单通道灰度图像。
- 该方法返回两个输出。第一个是使用的阈值,第二个输出是阈值后的图像。
1 | import cv2 |

自适应阈值
cv2.threshold:使用一个值作为全局像素的阈值,这样不能具备普适性,例如,图像在不同区域具有不同的光照条件时。cv2.adaptiveThreshold:基于像素周围的小区域确定像素的阈值。对于同一图像的不同区域,获取不同的阈值。cv2.ADAPTIVE_THRESH_MEAN_C:阈值是邻近区域的平均值减去常数C。cv2.ADAPTIVE_THRESH_GAUSSIAN_C:阈值是邻域值的高斯加权总和减去常数C。BLOCKSIZE:核大小,给定奇数边长。C:从邻域像素的平均或加权总和中减去的常数。
1 | import cv2 |

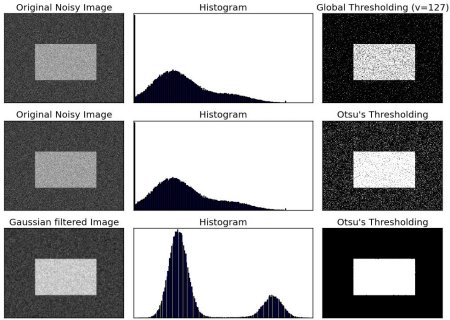
Otsu二值化(大津法)
Otsu方法将考虑仅具有两个主要的不同像素值的图像(双峰图像),即直方图仅包含两个峰。
cv2.threshold(img, thresh, maxval, type=cv2.THRESH_BINARY + cv2.THRESH_OTSU):Otsu二值化,从图像直方图中自动确定最佳全局阈值以区分这两个值,而无需手动选择。找到最佳阈值后,使用的阈值将作为第一输出返回。cv2.THRESH_OTSU:作为附加标志传递,实质上是int类型相加。
1 | import cv2 |
图像卷积
模糊、滤波与卷积的区别
图像卷积的本质,是提取图像不同『频段』的特征。https://zhuanlan.zhihu.com/p/28478034
图像模糊(平滑)和滤波,都属于卷积,不同滤波方法之间只是卷积核不同。
低/高通滤波概念
图像滤波既可以在实域进行,也可以在频域进行。通过滤波,可以强调一些特征或者去除图像中一些不需要的部分。
滤波是一个邻域操作算子,利用给定像素周围的像素的值决定此像素的最终的输出值。
高通滤波器(HPF):根据中心像素与周围像素的亮度差值来提升像素的亮度,保留变化强烈的部分,过滤缓和部分。用于:增强、锐化、边缘提取。
通过高通滤波器进行滤波后,再和原图像叠加,可以增强图像中灰度级变化较快的部分。
低通滤波器(LPF):当中心像素与周围像素的亮度差值大于一个特定值时,平滑该像素的亮度。用于:平滑、模糊、去除噪点。
低通滤波器容许低频信号通过,但截止了高频信号(噪音,边界)。
自定义滤波
cv2.filter2D(src, ddepth, kernel):将内核与图像进行卷积。ddepth:表示目标图像的所需深度。 当ddepth=-1时,表示输出图像与原图像有相同的深度。kernel:滤波器/卷积核。如果要将不同的内核应用于不同的通道,需要将图像拆分为单独的颜色平面,分别处理。
- 在OpenCV中可以自己定义滤波器,然后使用
filter2D()对一幅图像进行卷积操作。
1 | import cv2 |

常用的图像滤波
线性滤波(方框滤波、均值滤波、高斯滤波)、非线性滤波(中值滤波、双边滤波)
方框滤波
方框滤波即一个具有相同权重的二维矩阵。
大小 3x3 、权重为 a 的kernel:
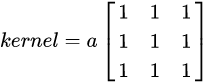
cv2.boxFilter(src, ddepth, ksize, normalize):当可选参数normalize=True时,方框滤波就是均值滤波,a=1/9;normalize=False时,a=1,相当于求区域内的像素和。
均值滤波
cv2.blur(src, ksize):对图像进行均值滤波,即将图像与归一化框滤波器进行卷积。- 保持这个kernel在一个像素点上,获取内核区域下所有像素的平均值,并替换中心元素。
1 | import numpy as np |

高斯模糊
- 不同于均值滤波,高斯滤波的卷积核权重:中间像素点权重最高,远离中心的像素根据离中心的距离递减,符合正态分布。
- 均值滤波是求平均数,高斯滤波是高斯求加权平均数。
cv2.GaussianBlur(src, ksize, sigmaX):高斯滤波可以有效的从图像中去除高斯噪音。- 高斯核的宽和高(必须是奇数)
- 高斯函数沿 X,Y 方向的标准差。如果只指定了 X 方向的的标准差,Y 方向也会取相同值。如果两个标准差都是 0,那么函数会根据核函数的大小自动计算。
cv.getGaussianKernel():构建一个高斯内核。
1 | blur = cv2.GaussianBlur(img, (5, 5), 0) |

中位模糊
cv2.medianBlur():中值模糊,保证了中心元素不会是新计算的值,而是该内核区域中所有像素的中值。- 很容易消除掉孤立的斑点(如0或255),对于消除椒盐噪声和斑点噪声非常有效。
- 中值是一种非线性操作,效率相比线性滤波要慢。
1 | median = cv2.medianBlur(img, 5) |

1 | def sp_noise(image, prob): |
双边滤波
- 高斯滤波器是求中心点邻近区域像素的高斯加权平均值,只考虑像素之间的空间关系(平面上的距离),而不会考虑像素值之间的关系(像素值之间的相似度/强度差)。
- 所以使用线性滤波器进行模糊无法判断一个像素是否位于边界,基本都会损失掉图像细节信息,边缘信息很难保留下来。
- 双边滤波同时使用空间高斯权重和灰度值相似性高斯权重。空间高斯函数确保只有邻近区域的像素对中心点有影响,灰度值相似性高斯函数确保只有与中心像素灰度值相近的才会被用来做模糊运算。由于边缘的像素强度变化较大,因此可以保留边缘。
- 双边滤波属于非线性滤波,相比线性滤波会比较慢。
cv2.bilateralFilter():双边滤波。保持边界清晰的情况下有效去除噪音。d:邻域直径sigmaColor:空间高斯函数标准差sigmaSpace:灰度值相似性高斯函数标准差
1 | bilateralFilter = cv2.bilateralFilter(img, d=9, sigmaColor=75, sigmaSpace=75) |

形态学转换
理论
- 形态学操作是根据图像形状进行的简单操作。
- 常见图像形态学运算:腐蚀、膨胀、开运算、闭运算、骨架抽取、极线腐蚀、击中击不中变换、Top-hat变换、颗粒分析、流域变换、形态学梯度等。
- 最基本的形态学操作是:膨胀(dilation)和腐蚀(erosion)。
- 形态学转换在一般情况下是对二值化图像进行操作。
- 腐蚀和膨胀是对像素值大的部分而言的,即白色(255)部分而不是黑色(0)部分。
- 膨胀就是图像中的高亮部分进行膨胀,效果图拥有比原图更大的白色区域。
- 腐蚀就是原图中的高亮部分被腐蚀,效果图拥有比原图更小的白色区域。
结构元素
形态学操作其实也是将图像与核进行卷积。
核(即结构元素/模板/掩码)可以是任何的形状(矩形/椭圆/十字形)和大小,其中心点称为锚点(anchorpoint)。
cv2.getStructuringElement(shape, ksize):生成不同形状的结构元素。shape:形状。ksize:大小。
1 | # 矩形内核 |
常用的形态学转换
cv2.morphologyEx(src, op, kernel):形态学转换方法op:形态学运算类型。可选包括 侵蚀、膨胀、开闭运算等等。
侵蚀
- 侵蚀前景(白色)物体的边界。
- 对于原始图像中的每个像素点,内核下的所有像素只要有一个像素为0,则像素元素为0。
- 效果:1. 分离出两个独立对象;2. 消除孤立的白色噪点;3. 白色物体中的黑色空洞会被扩大。
1 | import cv2 |

扩张
- 扩张前景(白色)物体的边界。
- 对于原始图像中的每个像素点,内核下的所有像素只要有一个像素为1,则像素元素为1。
- 效果:1. 连接两个对象为一个整体;2. 填补白色物体中的黑色空洞;3. 主体外区域的白色噪点会被放大。
1 | dilation = cv2.dilate(img, kernel=kernel, iterations=1) |

开运算
- 开运算 等价于 侵蚀×1+扩张×1。
- 开运算×1 等价于 开运算×n。
- 作用:1. 消除目标外的背景噪音、孤立点;2. 平滑物体轮廓(如果边缘上有凸起)。
- 注意:开运算过后的变量名不要设置为open,这与打开文件的方法名重复。闭运算同理。
- 开/闭运算的精髓在于对细小孤立的白/黑区域(即可能被看做前/背景的噪声)进行消除,而对连续平滑的主体不产生影响。
- 对一张黑白图进行开运算 等价于 对其反色的图进行闭运算。
1 | # morphologyEx |

闭运算
- 闭运算 等价于 扩张×1+侵蚀×1。
- 闭运算×1 等价于 闭运算×n。
- 作用:1. 填补目标内部的黑洞、连接目标裂缝;2. 平滑物体轮廓(如果边缘上有凹陷)。
1 | # morphologyEx |

梯度
- 基本梯度 等价于 膨胀后的图像减去腐蚀后的图像。表现图像扩张和侵蚀之间的区别,
- 作用:提取对象的轮廓。
1 | # morphologyEx |

顶帽
- 顶帽 等价于 源图像减去开运算后的图像。
- 作用:显示开操作所去掉的白噪点。
1 | # morphologyEx |

黑帽
- 黑帽 等价于 闭运算后的图像减去源图像。
- 作用:显示闭操作所填充的黑洞及裂缝。
1 | # morphologyEx |
