Django-Part2
Django-Part2——路由层
[TOC]
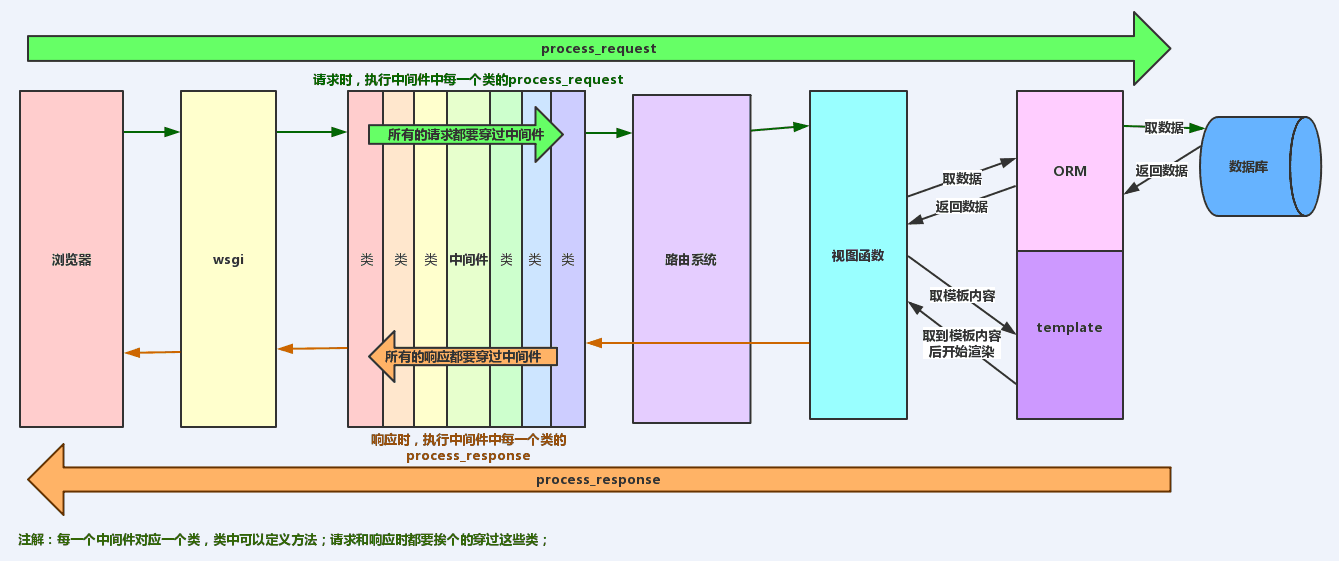
Django请求生命周期流程图(重点)
- wsgiref模块能够支持的并发量很小,上线之后换成uwsgi
- wsgi、wsgiref、uwsgi之间的关系
- wsgi是协议
- wsgiref和uwsgi是实现该协议的功能模块
路由匹配
path()/re_path()与url()
- 匹配顺序从上到下,只要能够匹配到内容,那么就会立刻停止往下匹配。
- 2.x之后的
re_path()与1.x的url()是等价的,推荐使用新版本的方法,方法名更加容易辨别意思。 re_path()的第一个参数是正则表达式,一旦匹配到了,则进入响应的视图函数并停止匹配。path()的第一个参数是路径,只有完全匹配时才会执行对应的视图函数。
1 | from django.contrib import admin |
- 在访问url时会以输入的原url进行一次匹配。当匹配失败时,会在原url上添加后缀
/,再次进行一次匹配。
1 | # 取消自动加斜杠,默认为True |
无名分组
- 无名分组就是将括号内正则表达式匹配到的内容当作位置参数传递给后面的视图函数
1 | # -> urls.py |
有名分组
- 有名分组就是将括号内正则表达式匹配到的内容当作关键字参数传递给后面的视图函数
- 需要有一个对应的形参来接收
1 | # -> urls.py |
无名有名是否可以混合使用
- 不能混用无名、有名分组
- 但是只使用一种分组时可以使用多次/传多个形参
1 | # -> urls.py |
反向解析
别名
- 通过一些方法得到一个结果 该结果可以直接访问对应的url触发视图函数
1 | # -> urls.py |
无名分组反向解析
分组的解析值一般就是数据的主键值。
1 | # -> urls.py |
有名分组反向解析
1 | # -> urls.py |
如何理解分组反向解析
- 分组是基于正则表达式匹配url,即不同的url能够进入相同的视图函数,多存在于
https://xxx/id/类似,这部分会在id不同时发生变化。 - 反向解析基于别名,在.html和.py中动态获得
https://xxx/id/的xxx部分,这部分可能会在重构url地址时发生变化。 - 分组反向解析则是通过上述两条结合,动态地获得
https://xxx/id/这条有很多种可能的url,以方便进入相应的视图函数。 - 分组的解析值一般就是数据的主键值,相当于是在视图函数中增加形参,来代替在request中获取的部分数据。
路由分发
include()
- django的每一个应用都可以有自己的templates、urls.py、static(需要自己新建)。这样能够很好地做到分组开发,最终利用路由分发进行整合。
- 当django项目中的url特别多的时候,总路由urls.py代码非常冗余不好维护,这时也可以利用路由分发来减轻总路由的压力。
- 使用路由分发之后,总路由不再将url与视图函数直接对应,而是识别分类当前url所属应用,并分发给对应的应用去处理。
1 | # 总路由 |
名称空间
- 当多个应用出现了相同的别名,反向解析只能识别后缀而不能识别前缀,例如
https://app/xxx/
1 | # 总路由 |
- 利用名称空间可以区分不同app的相同别名,但一般只需要在别名之前添加所属应用作为前缀,就大可不必使用名称空间。
1 | # -> urls.py |
伪静态
- 静态网页:数据是写死的 万年不变
- 伪静态:将一个动态网页伪装成静态网页
- 伪装的目的:
- 增大本网站的seo查询力度
- 增加搜索引擎收藏本网上的概率
1 | # 仅将url地址改为.html结尾,假装只是返回html文件,实际上还是经过视图函数,可以做动态处理 |
虚拟环境
- 在正常开发中,通常每一个项目配备一个独有的解释器环境,只有该项目用到的模块,用不到一概不装。
- 但是较多的虚拟环境会消耗更多的硬盘空间。
- 一般通过requirement.txt来标识项目的虚拟环境需要的模块。
path()转换器
- str:匹配除了路径分隔符
/之外的非空字符串,这是默认的形式 - int:匹配正整数,包含0。
- slug:匹配字母、数字以及横杠、下划线组成的字符串。
- uuid:匹配格式化的uuid,如:075194d3-6885-417e-a8a8-6c931e272f00。
- path:匹配任何非空字符串,包含了路径分隔符(/)
1 | # -> urls.py |
- 自定义转换器
1 | # -> path_converts.py |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 浅幽丶奈芙莲的个人博客!