浙江大学机器学习课程Part4
浙江大学机器学习课程Part4——深度学习
[TOC]
多层神经网络的优劣
多层神经网络的优势
- 基本单元简单,多个基本单元可扩展为非常复杂的非线性函数。因此易于构建,同时模型有很强的表达能力。
- 训练和测试的计算并行性非常好,有利于在分布式系统上的应用。
- 模型构建来源于对人脑的仿生,话题丰富,各种领域的研究人员都有兴趣,都能做贡献。
多层神经网络的劣势
- 数学不漂亮,优化算法只能获得局部极值,算法性能与初始值有关。
- 不可解释。训练神经网络获得的参数与实际任务的关联性非常模糊。
- 模型可调整的参数很多 (网络层数、每层神经元个数、非线性函数、学习率、优化方法、终止条件等等),使得训练神经网络变成了一门“艺术”。
- 如果要训练相对复杂的网络,需要大量的训练样本。
数据库
- Mnist:手写数字数据库(LeCun 在1998年创造)
- ImageNet:(Fei-fei Li等 2007年创造)
发展历史
现状
神经网络是目前处理大数据最优的算法。
模拟退火和遗传算法还处于沉寂期。
转机
2006年是深度学习的起始年,Hinton在SCIENCE上发文,提出一种叫做自动编码机(Auto-encoder)的方法,部分解决了神经网络参数初始化的问题。
但是目前为止,自动编码机并没有什么用。
卷积神经网络(CNN)
发展
是深度学习神经网络流行起来最大的因素。
由手工设计卷积核变成自动学习卷积核。
如何卷积
一个讲解比较清晰的视频:什么是卷积?
详细图解原理在另一份笔记中,不重复记述:PyTorch深度学习实践Part10
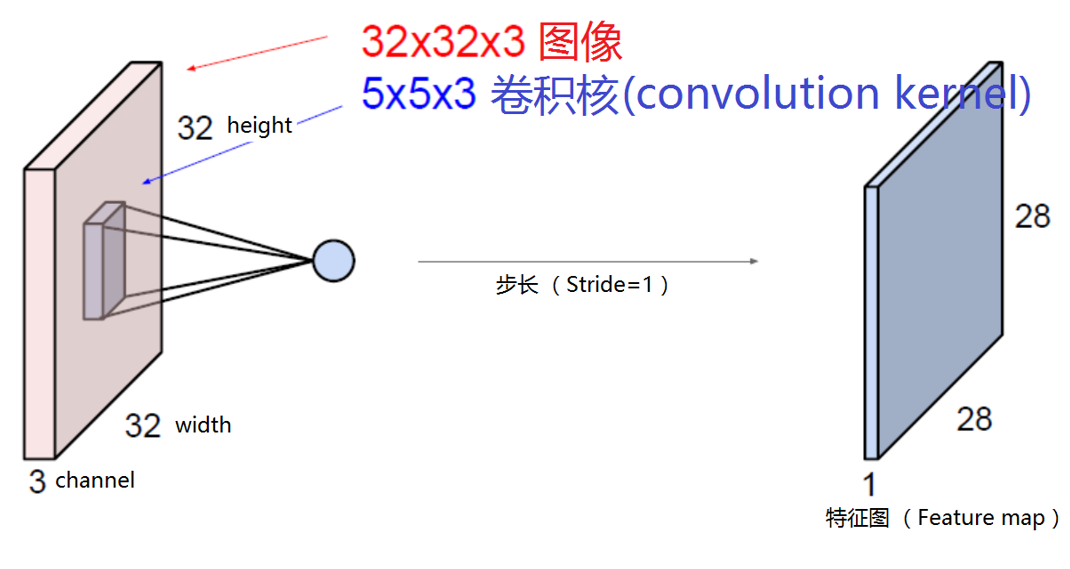
卷积核的数量等于输出通道数。卷积核的长度等于输入通道数。
卷积过后得到的叫做特征图。
在边缘可能会丢失数据的时候,用padding补零。
区别
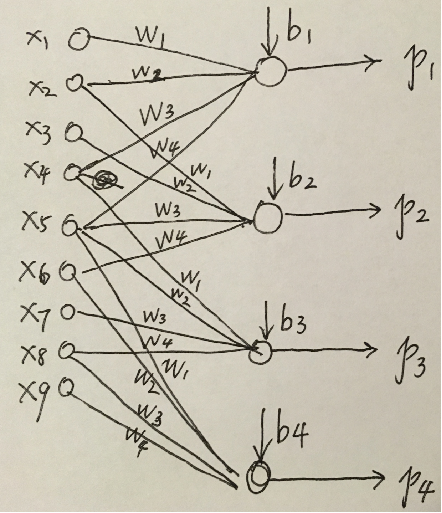
卷积神经网络与全连接的区别。
- 局部感受野
- 权值共享
卷积虽然复杂,但是计算量更少。
激活
在卷积神经网络中,最常用的非线性函数为ReLu。
后向传播
导数会平均反向传播。
整个网络的计算速度取决于卷积层,整个网络的参数个数取决于全连接层。
即:如果要加速神经网络,则在卷积层做文章;如果要让其内存占用更少的话,则在全连接层做文章。
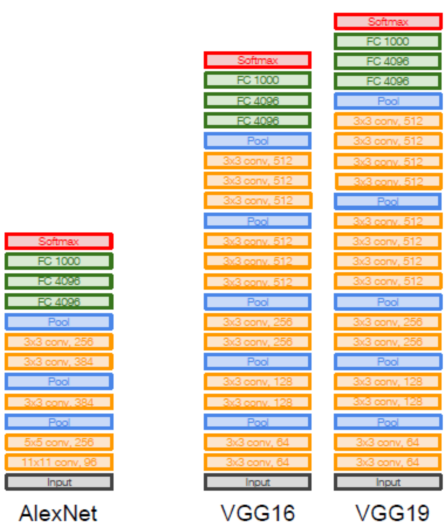
AlexNet
改进1——ReLU
以ReLU函数代替sigmoid或tanh函数。
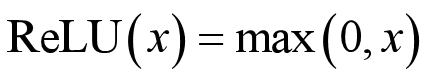
实践证明,这样做能使网络训练以更快速度收敛。
如果数据是靠近0的正态分布,则每次只激活一半的神经元。
改进2——MaxPooling
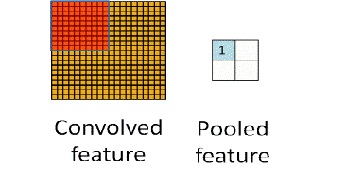
在AlexNet中,提出了最大池化(Max Pooling)的概念,即对每一个邻近像素组成的“池子”,选取像素最大值作为输出。在LeNet中,池化的像素是不重叠的;而在AlexNet中进行的是有重叠的池化。实践表明,有重叠的最大池化能够很好的克服过拟合问题,提升系统性能。
在反向传播时,只传播最大值,其他都为0。
MaxPooling不仅是一个降采样的操作,同时还是一个非线性操作。只采用最大的神经元,有效降低了激活的神经元个数,从而加快了收敛的速率。
改进3——Dropout
随机丢弃(Dropout)。为了避免系统参数更新过快导致过拟合,每次利用训练样本更新参数时候,随机的“丢弃”一定比例的神经元,被丢弃的神经元将不参加训练过程,输入和输出该神经元的权重系数也不做更新。这样每次训练时,训练的网络架构都不一样,而这些不同的网络架构却分享共同的权重系数。实验表明,随机丢弃技术减缓了网络收敛速度,也以大概率避免了过拟合的发生。
道理和改进2一样,每次训练都只激活有限个神经元,而不要让整个网络同时改变所有的参数,导致整个网络不稳定。
改进4——增加训练样本
增加训练样本。尽管ImageNet的训练样本数量有超过120万幅图片,但相对于6亿待估计参数来说,训练图像仍然不够。Alex等人采用了多种方法增加训练样本,包括:1. 将原图水平翻转;2. 将256×256的图像随机选取224×224的片段作为输入图像。运用上面两种方法的组合可以将一幅图像变为2048幅图像。还可以对每幅图片引入一定的噪声,构成新的图像。这样做可以较大规模增加训练样本,避免由于训练样本不够造成的性能损失。
改进5——GPU加速
用GPU加速训练过程。采用2片GTX 580 GPU对训练过程进行加速,由于GPU强大的并行计算能力,使得训练过程的时间缩短数十倍,哪怕这样,训练时间仍然用了六天。
近年来流行的网络结构
VGGNet: (Simonyan and Zisserman, 2014)
3个叠到一起的3 * 3卷积核,感受野(Receptive Field)是7 * 7,大致可以替代7 * 7卷积核的作用。但这样做可以使参数更少 ,参数比例大致为27:49。
但是,运算速度会因为卷积核数量的增加而大幅下降。
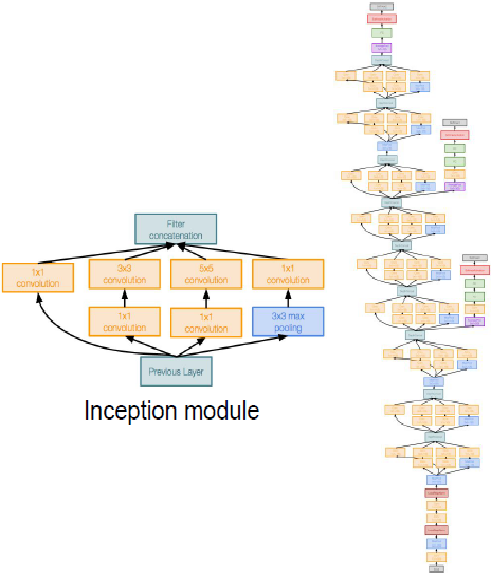
GoogLeNet: (Szegedy, 2014)
inception 结构,用一些11, 33和5*5的小卷积核用固定方式组合到一起,来代替大的卷积核,从而达到增加感受野和减少参数的目的。500万参数,比ALEXNET小了12倍。
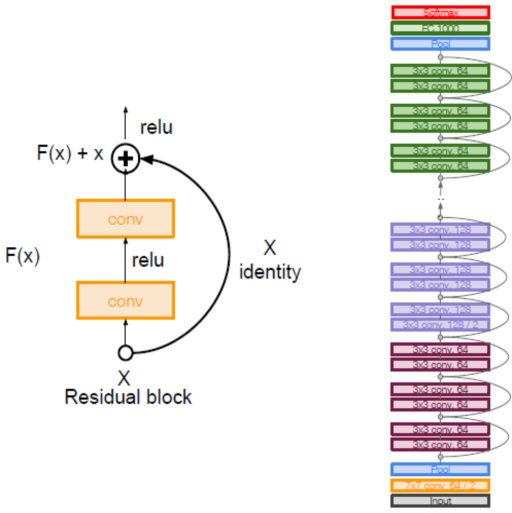
残差网络Residual Net(ResNet): (He et al, 2015)
加入了前向输入机制,将前面层获得的特征图作为监督项输入到后面层。用这样的方法使深层网络训练能够更好地收敛。
迁移学习(Transfer Learning )
迁移学习是指,从一个domain训练好的神经网络,加入新的domain的样本进行调优,从而获得一个更好的识别效果。
例如,训练好的 Alex Net ,在最后的1k个分类后,外加一层全连接神经网络,输出十几种水果的分类,用十种水果进行调优。虽然这原本1k个分类中或许没有很明显的这十几种水果分类,但这样它能很容易排除除了这些水果以外的物品,同时经过调优之后会更容易贴合我们想要分出的十几种水果。
目标检测与分割
这里其实算深度学习(
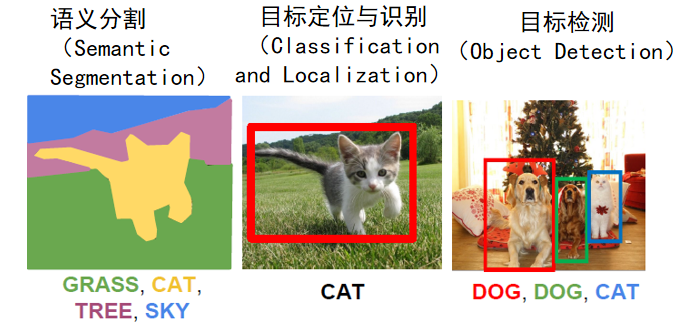
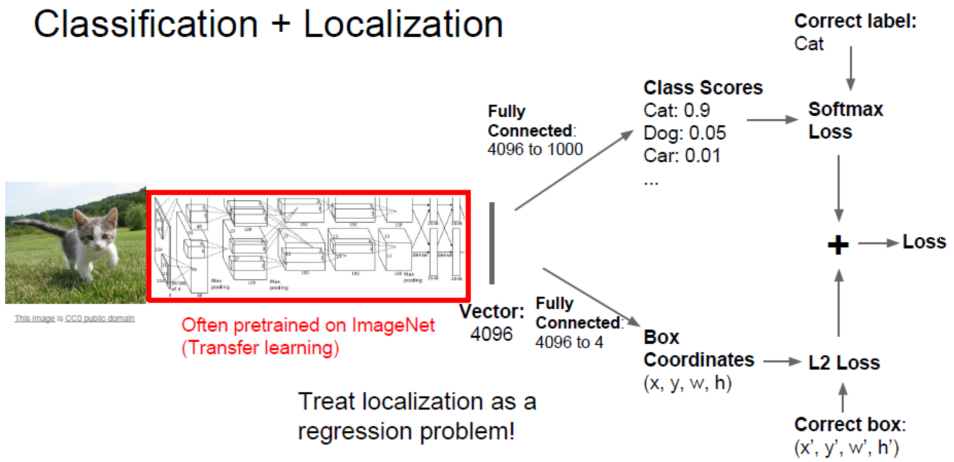
目标定位与识别
目标检测
在一幅图片中可能有多种类别,不能确定数量。
现在这个问题基本解决,有三篇逐步递进的三篇论文。
Regional CNN(R-CNN)
目标候选区域(Region Proposal):先用传统方法或者图像处理的方法,确定可能有物体的地方候选项,再放在卷积神经网络检测。
步骤
- Selective Search:产生RP
- CNN:检测这些候选区域
- SVM:分类
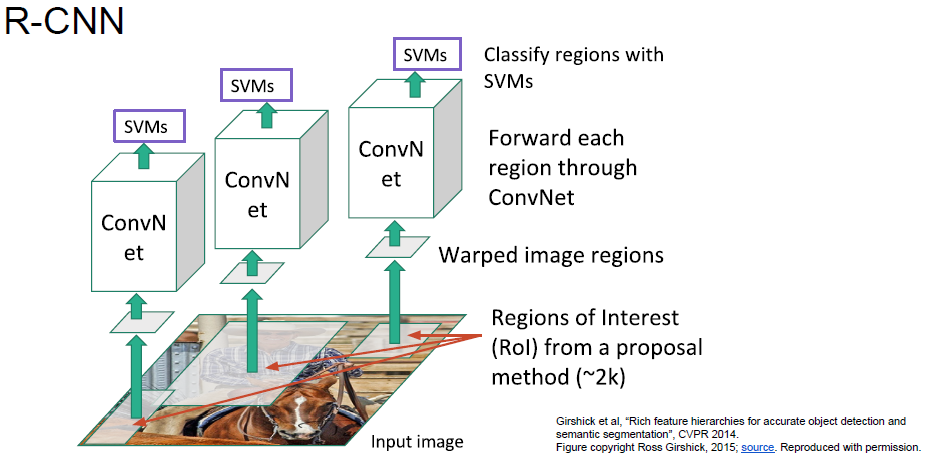
缺陷
- High cost to perform Selective Search (~5s per image)
- Too many passes to CNN (~2000 proposals per image)
- Lead to unacceptable test time (~50s per image)
- High space cost to train SVM (millions of 1024-d features)
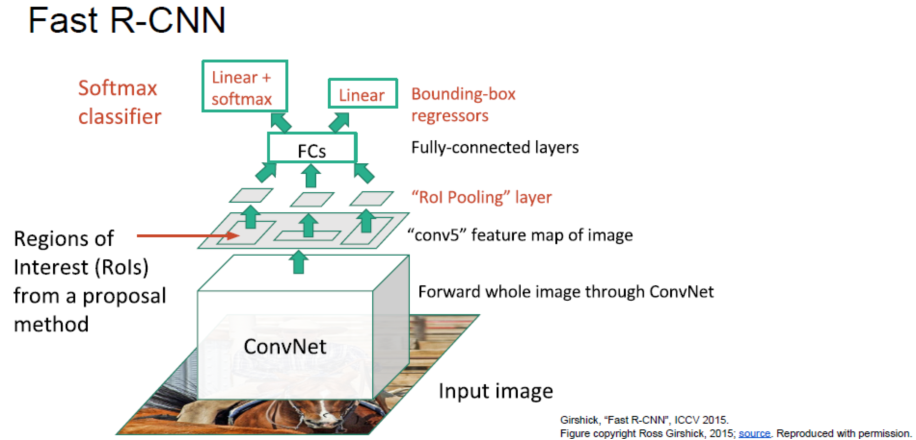
Fast R-CNN
用 Regions of Interest(RoIs) 把不同长宽的候选区域,在Pooling层归一化成同一形状。最后依然是一路预测label,一路预测Bounding-box regressors。
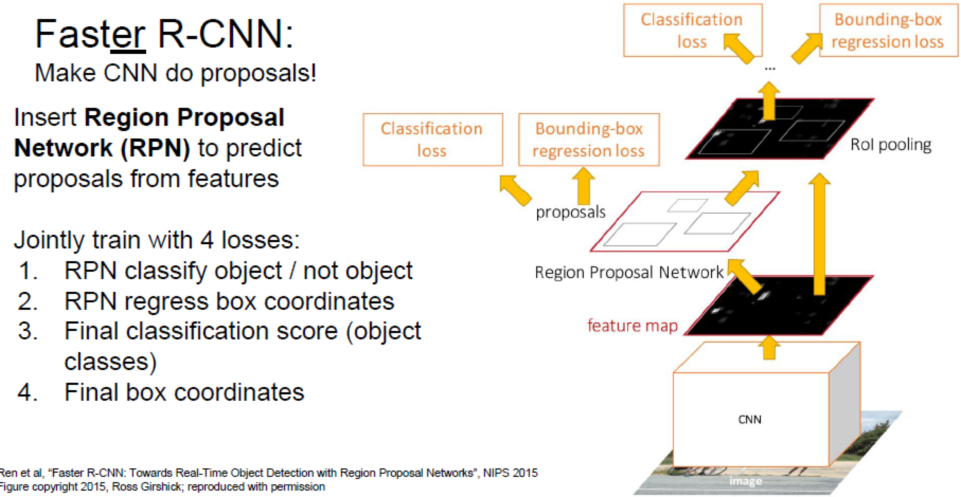
Faster R-CNN
主要通过小的Region Proposal Network产生粗略位置,来代替Selective Search
语义分割
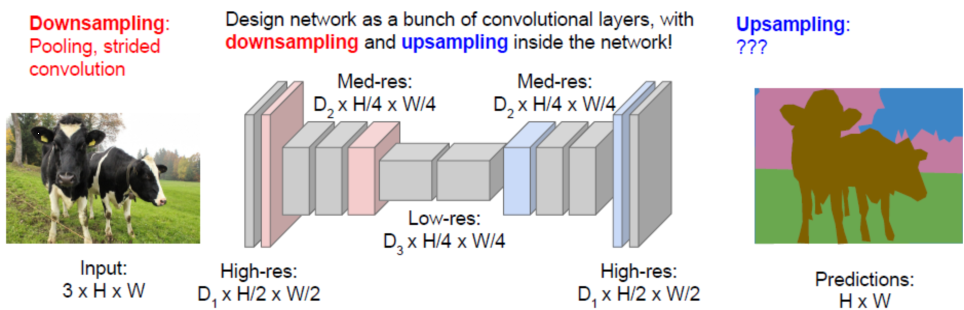
全卷积网络FCN
全卷积网络(Fully Convolutional Networks)
先训练前面一半,再训练后一半。先降采样,后升采样。
卷积层的上采样(Upsampling)也叫反卷积(Deconvolution)或 转置卷积(Transpose Convolution)。
全卷积网络也可以用于边缘提取。
隐含马尔科夫过程(HMM)与递归神经网络(RNN)
对连续信息的判断有几个问题:不知道如何划分每一个状态,因为①持续时间可能各不相同;②对于语音模型的建模是以一个音节而不是一个单词为基础。
Hidden Markov Models==复习==
一个HMM模型是由三部分组成:λ = {A, B, π}。其中,A为状态转移矩阵,B为观测概率,π为状态先验概率。
- π(S
i)表示一开始在Si状态的概率。 - A是一个P×P的矩阵。马尔科夫链假设是强假设,后一个时刻状态和前一个(或者多个)时刻状态有关(注意这是固定假设 a
i,j=P(qt+1=Sj|qt=Si)。当t时刻的q样本是状态为Si类,则在t+1时刻q样本转变为状态为Sj类的概率) - B={b
j(0)} 若输入向量O属于Sj,则它的概率分布用bj(0)表示。
大词汇量连续语音识别(LVCSR)
大词汇量连续语音识别(Large-scale Vocabulary Continuous Speech Recognition, LVCSR)
- 每一个HMM模型所表达的“单词”是什么?英语中有效的Triphone个数大致在55000左右,模型过多而训练样本不足,所以需要多个Triphone 合并(Tying)、多个Triphone 联合训练(Tying)
- 在识别流程中如何对测试声音文件做时间轴的划分,使每一个分段(SEGMENT)对应一个“单词”?如何搜索最佳的“单词”组合?VITERBI搜索(有多种形式,如Two-Level Dynamic Programming)、A*搜索、随机搜索
- 如何构造语言模型 (Language Model)? 定义(N-gram): 一个单词出现的概率,只与它前面的N个单词相关。
结合深度网络模型的语音识别

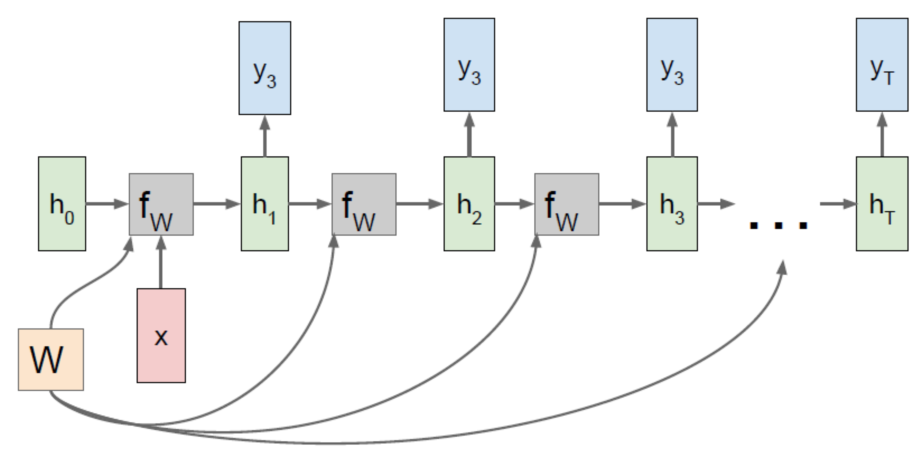
Recurrent Neural Network
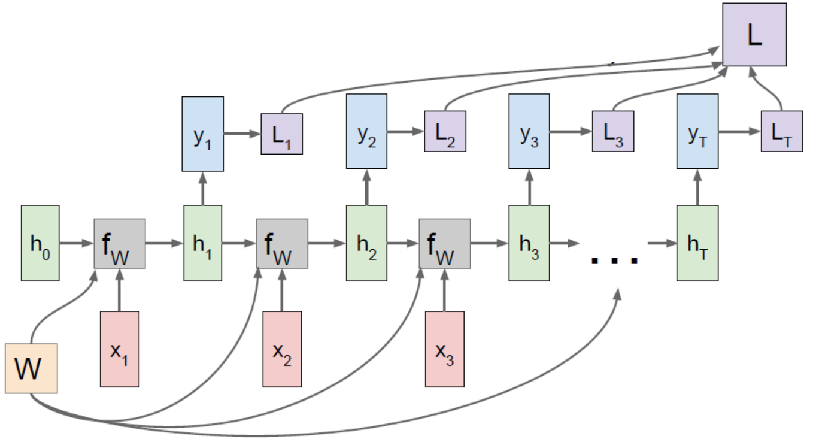
输入与输出多对多:
大词汇连续语音识别、机器翻译
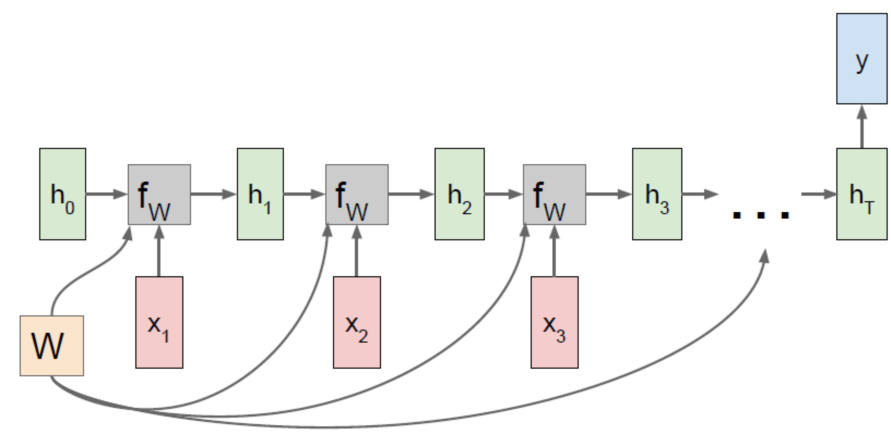
输入与输出多对一:
动作识别、行为识别、单词量有限的语音识别
输入与输出一对多:
文本生成、图像文字标注
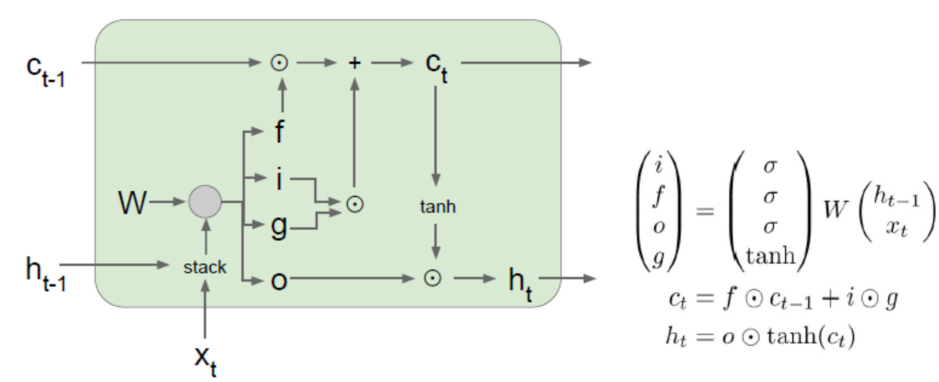
Long-Short Term Memory (LSTM)
相比VANILLA RNN, LSTM的误差反向传播更方便和直接,梯度更新不存在RNN中的暴涨或消失现象。因此,建议涉及RNN的应用都用LSTM或LSTM相关的变种。