PyTorch深度学习实践Part10
PyTorch深度学习实践Part10——卷积神经网络(基础篇)
Basic CNN
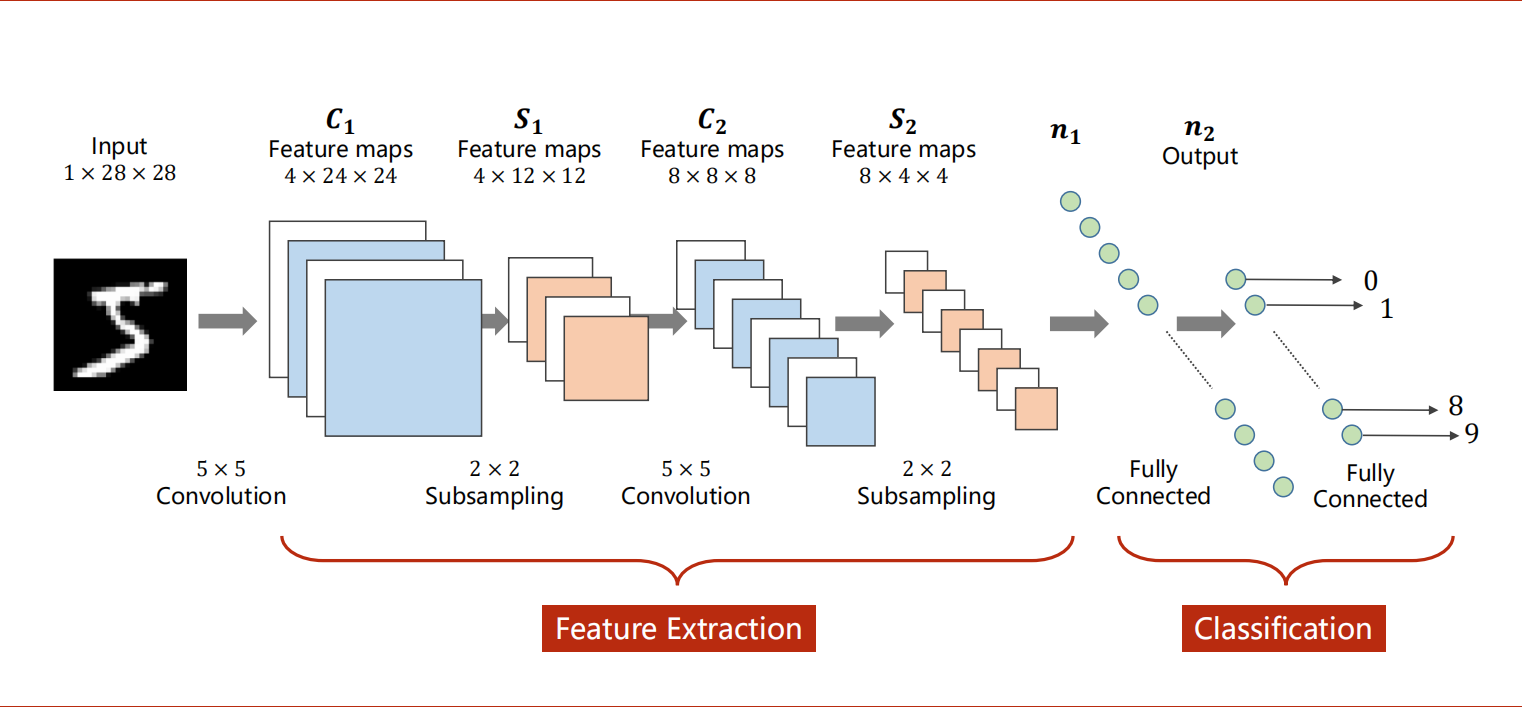
CNN(Convolutional Neural Network)结构:特征提取+分类。
通道(Channel)×纵轴(Width)×横轴(Height),起点为左上角。
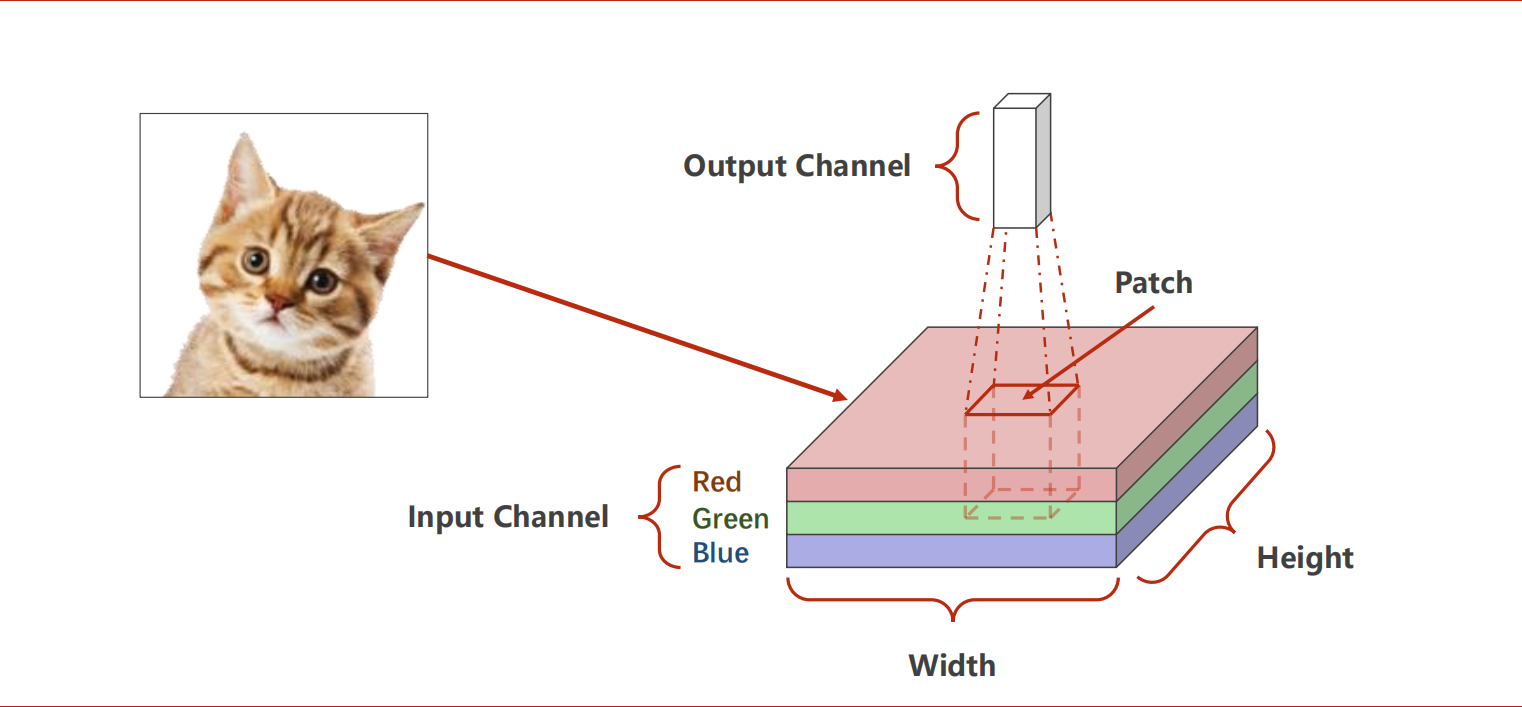
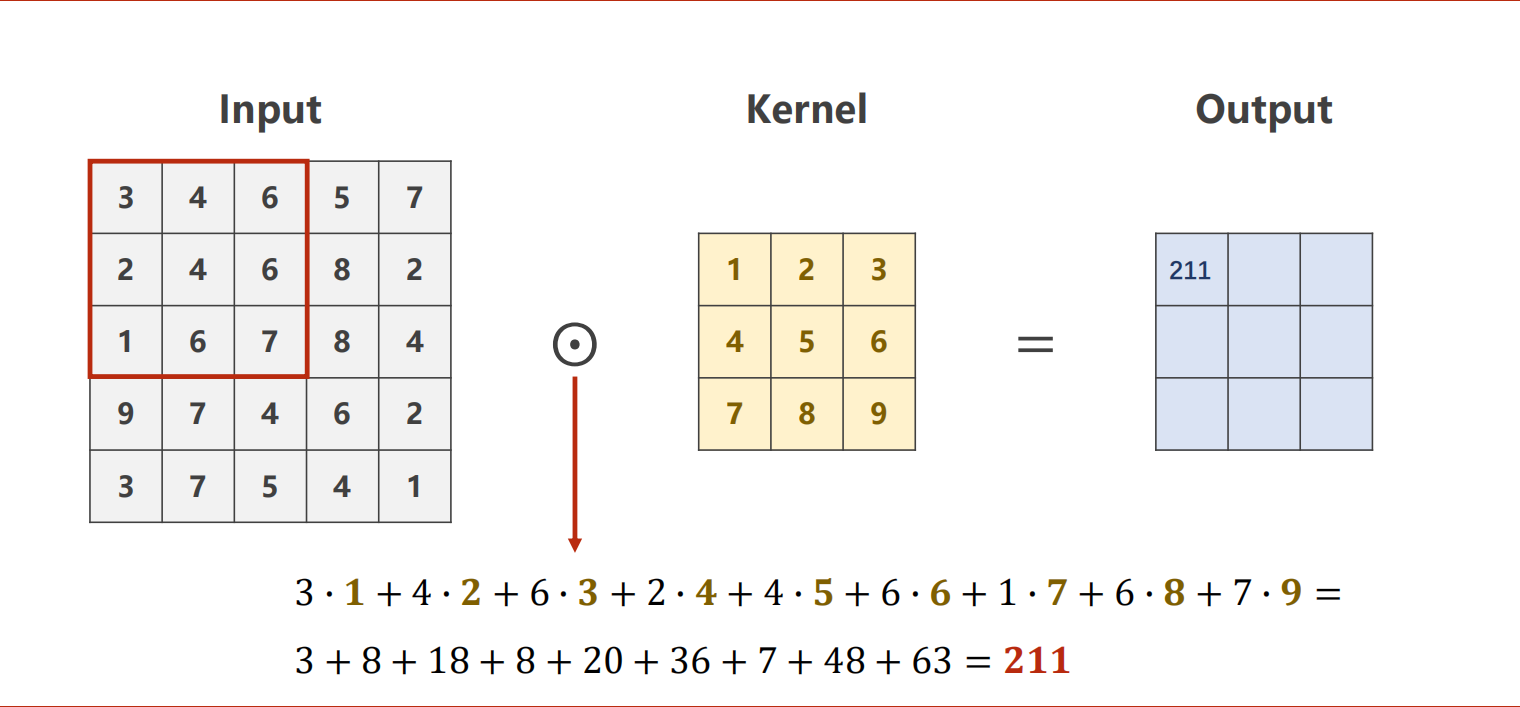
Patch逐Width扫描,矩阵作数乘(哈达玛积)。
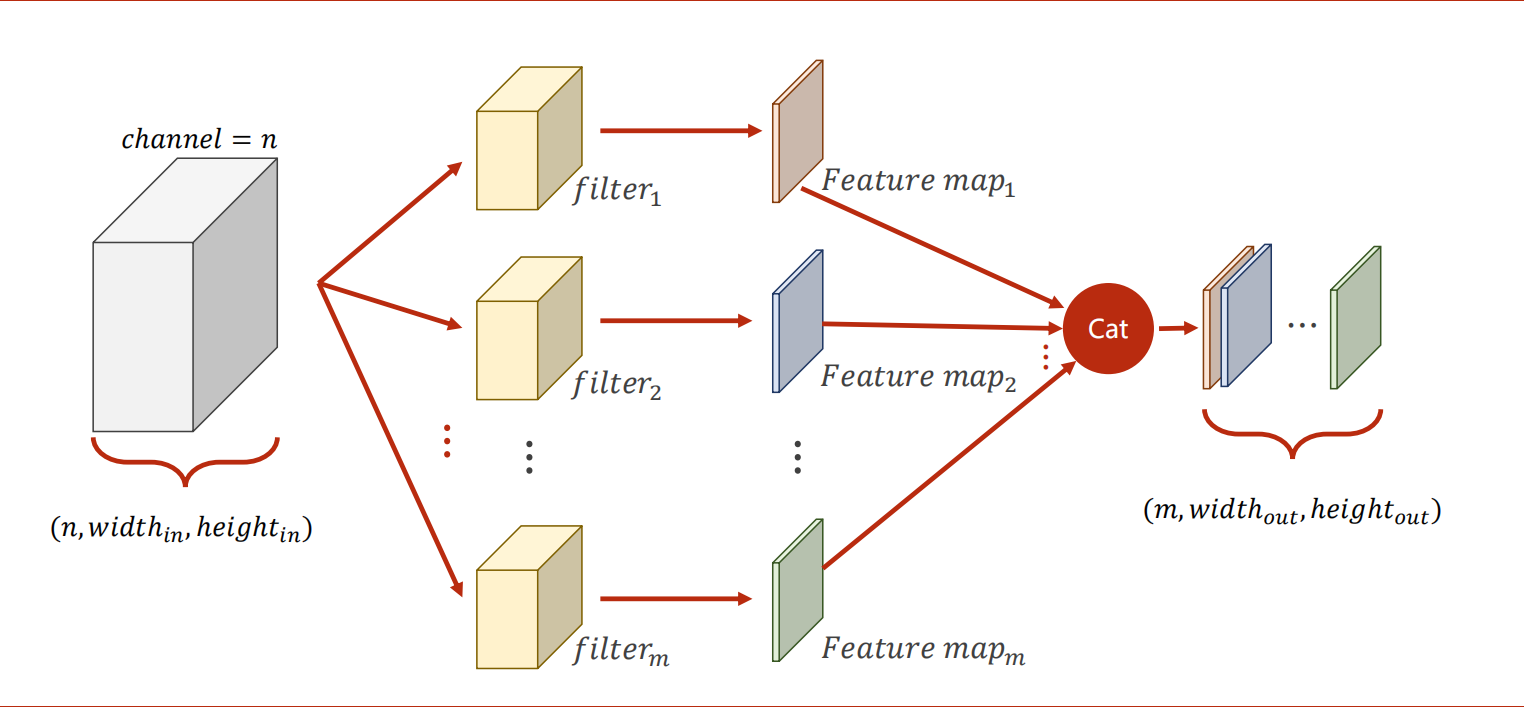
多通道的卷积中,每一个通道都要配一个卷积核,并相加。
深度学习里的卷积是数学中的互相关,但是惯例称为卷积,和数学中的卷积有点不同,但是不影响。
n*n的卷积核,上下各-(n-1)/2,原长宽-(n-1)。n一般采用奇数,卷积形状一般都是正方形,在pytorch中奇偶、长方形都行。
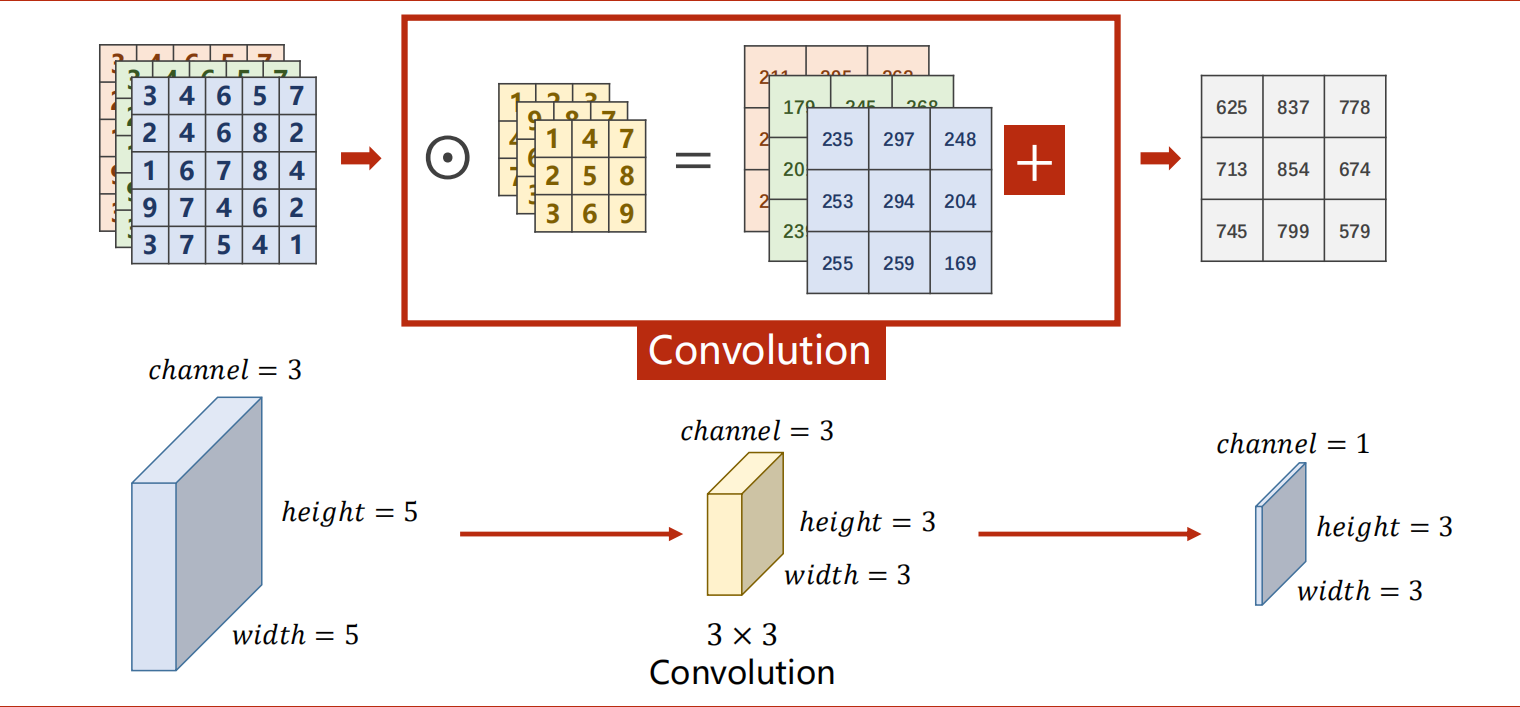
每一组卷积核的通道数量要求和输入通道是一样的。这种卷积核组的总数和输出通道的数量是一样的。卷积过后,通道就与RGB没有关系了。
卷积(convolution)后,C(Channels)变,W(width)和H(Height)可变可不变,取决于是否填充边缘(padding),不填充则会有边缘损失。
卷积层:保留图像的空间信息。卷积本质上也是线性计算,也是可以优化的权重。
卷积神经网络要求输入输出层是四维张量(Batch, Channel, Width, Height),卷积层是(m输出通道数量, n输入通道数量, w卷积核宽, h卷积核长),全连接层的输入与输出都是二维张量(B, Input_feature)。
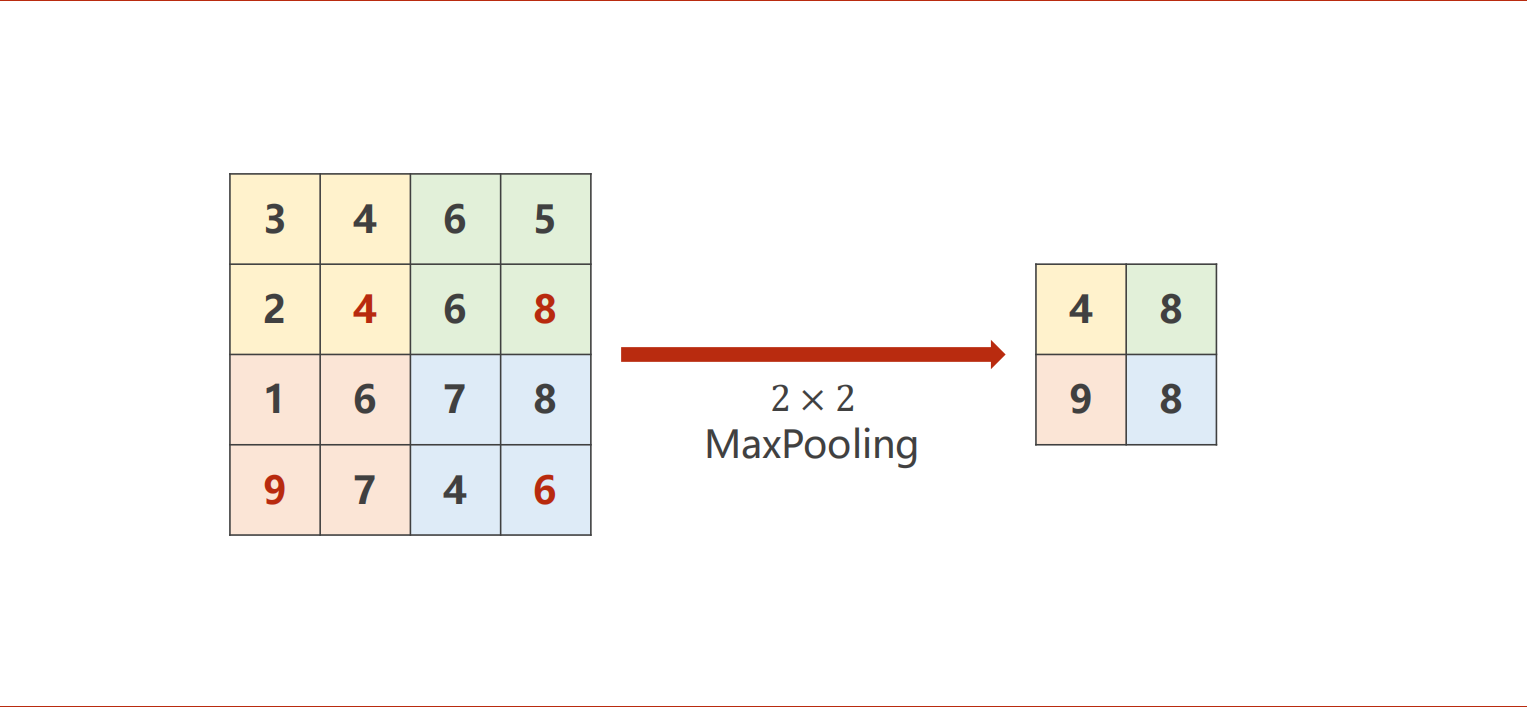
下采样(subsampling)或池化(pooling)后,C不变,W和H变成 原长度/池化长度。(MaxPool2d是下采样常用的一种,n*n最大池化默认步长为n)
池化层与sigmoid一样,没有权重。
卷积(线性变换),激活函数(非线性变换),池化;这个过程若干次后,view打平,进入全连接层。
1 | import torch |
代码实现
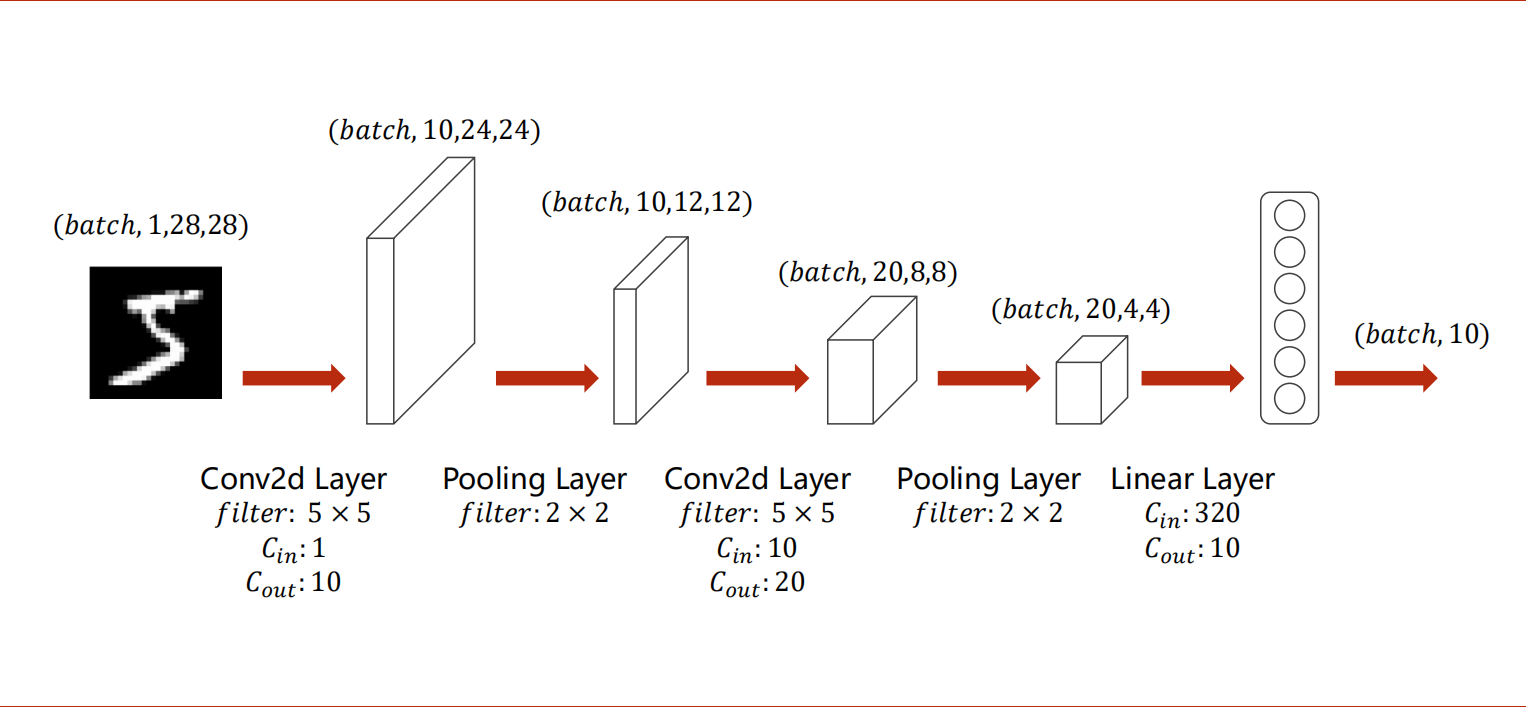

1 | import torch |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 浅幽丶奈芙莲的个人博客!