PyTorch深度学习实践Part5
PyTorch深度学习实践Part5——线性回归
PyTorch周期
- prepare dataset
- design model using Class 目的是为了前馈forward,即计算y hat(预测值)
- Construct loss and optimizer (using PyTorch API) 其中,计算loss是为了进行反向传播,optimizer是为了更新梯度。
- Training cycle (forward,backward,update)
广播
原本w只是1×1的矩阵,比如tensor([0.], requires_grad=True),很有可能行列数量与xy对不上,这个时候pytorch会进行广播,将w扩展成一个3×1矩阵。

pytorch直接写“*”表示矩阵对应位置元素相乘(哈达玛积),数学上的矩阵乘法有另外的函数torch.matmul
这里x、y的维度都是1(有可能不是1),但是都应当看成一个矩阵,而不能是向量。
x、y的列是维度/特征,行是记录/样本
模型
- 要把计算模型定义成一个类,继承于torch.nn.Model。(nn:neural network)
- 如果有pytorch没有提供的需求,或者其效率不够高,可以从Function中继承,构造自己的计算块。
- Linear类包括成员变量weight和bias,默认bias=True,同样继承于torch.nn.Model,可以进行反向传播。
- 权重放在x右边,或者转置放在左边。(不管怎么放都是为了凑矩阵基本积)
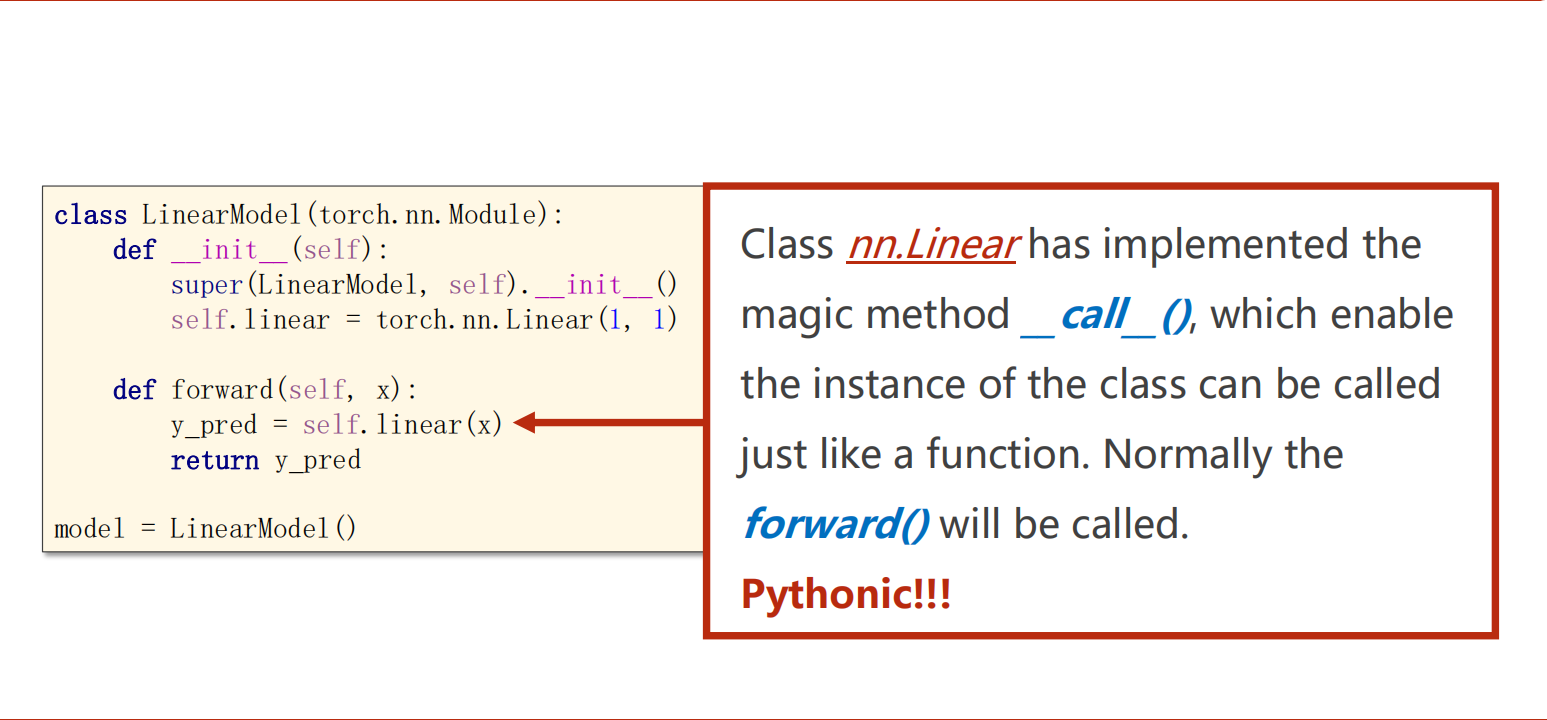
- 父类实现了callable函数,让其能够被调用。在call中会调用前馈forward(),所以必须重写forward()。
*args, **kwargs的用法:
1 | def fun(*args, **kwargs): |
损失&优化
- 计算损失使用现成的类 torch.nn.MSELoss 。
- 一般使用随机梯度下降算法,求和平均是没有必要的,torch.nn.MSELoss(size_average=False)
- 使用现成的优化器类torch.optim.SGD
- 不同的优化器,官方文档
- 控制训练次数,不能过少(训练不到位),也不能过多(过拟合)
代码实现
1 | import torch |
课后作业
测试不同的优化器。除了LBFGS,只需要修改调用对应优化器的构造器。
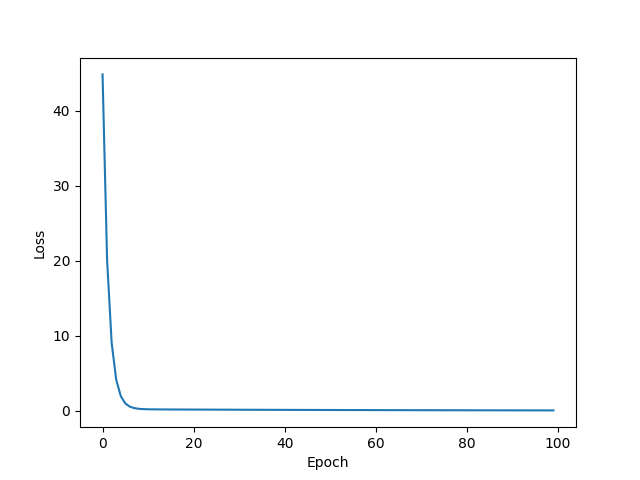
Adagrad
w = 0.20570674538612366
b = -0.5057424902915955
y_pred = 0.31708449125289917
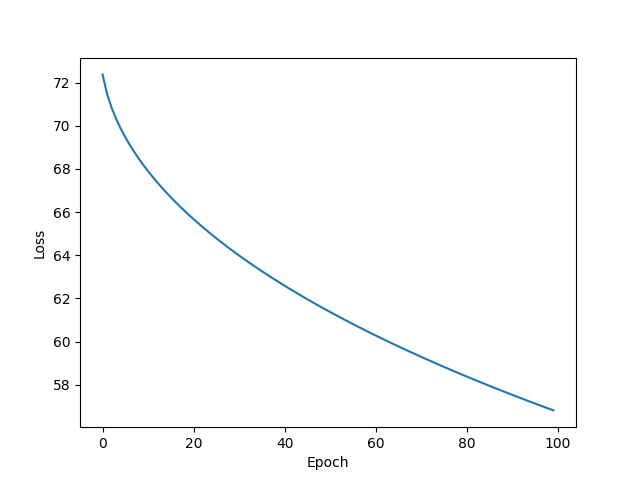
Adam
w = 1.466607928276062
b = 0.14079217612743378
y_pred = 6.007224082946777
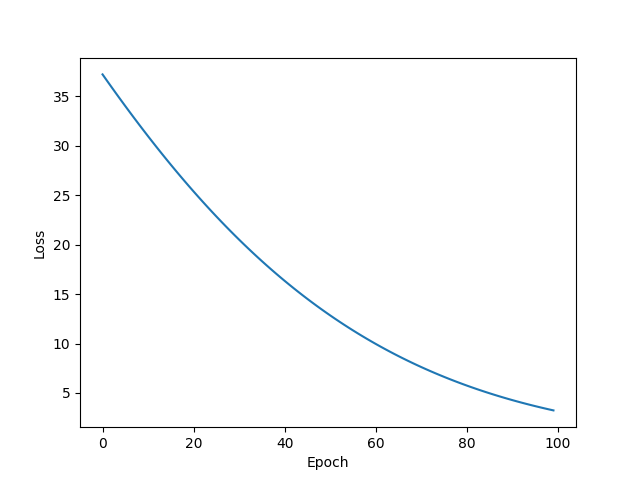
Adamax
w = -0.022818174213171005
b = 0.9245702028274536
y_pred = 0.8332974910736084
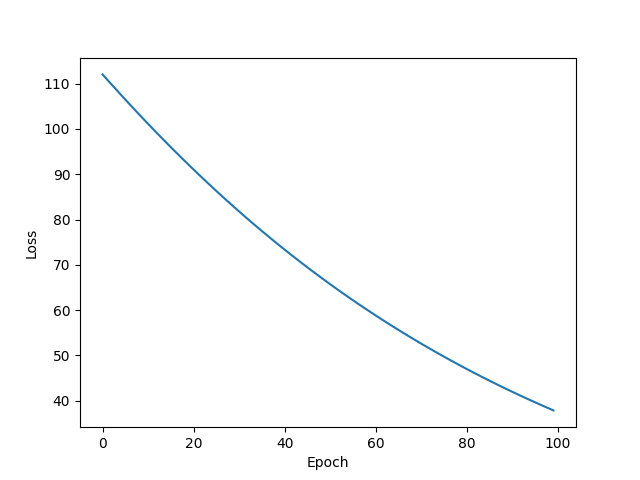
ASGD
w = 1.6153326034545898
b = 0.87442547082901
y_pred = 7.335755825042725
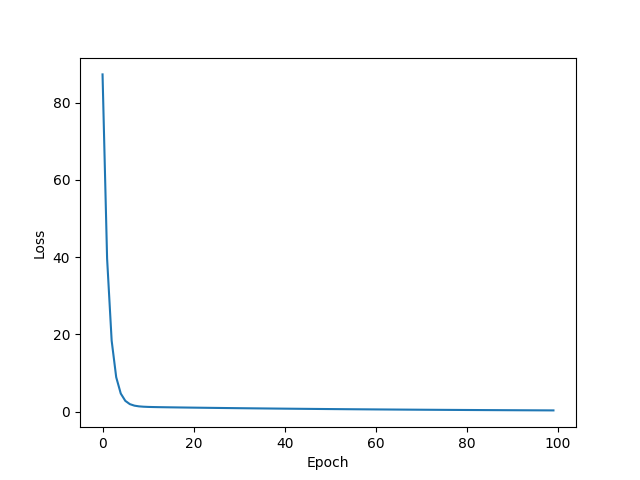
LBFGS
由于LBFGS算法需要重复多次计算函数,因此需要传入一个闭包去允许它们重新计算模型。这个闭包应当清空梯度, 计算损失,然后返回。
训练模型部分代码应修改为:
1 | def closure(): |
w = 1.7660775184631348
b = 0.531760573387146
y_pred = 7.596070766448975
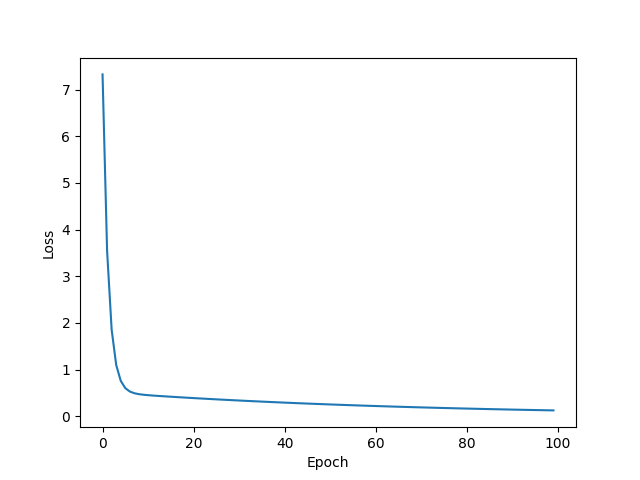
RMSprop
w = 1.734222650527954
b = 0.5857117176055908
y_pred = 7.522602081298828
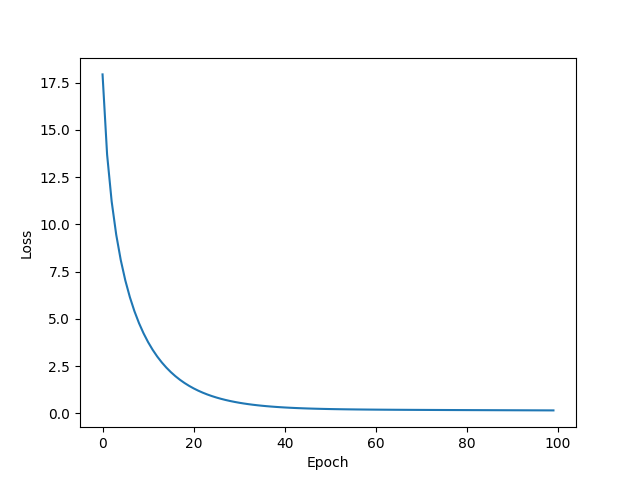
Rprop
w = 1.9997763633728027
b = 0.0004527860146481544
y_pred = 7.999558448791504
SGD
w = 1.8483222723007202
b = 0.3447989821434021
y_pred = 7.738088130950928