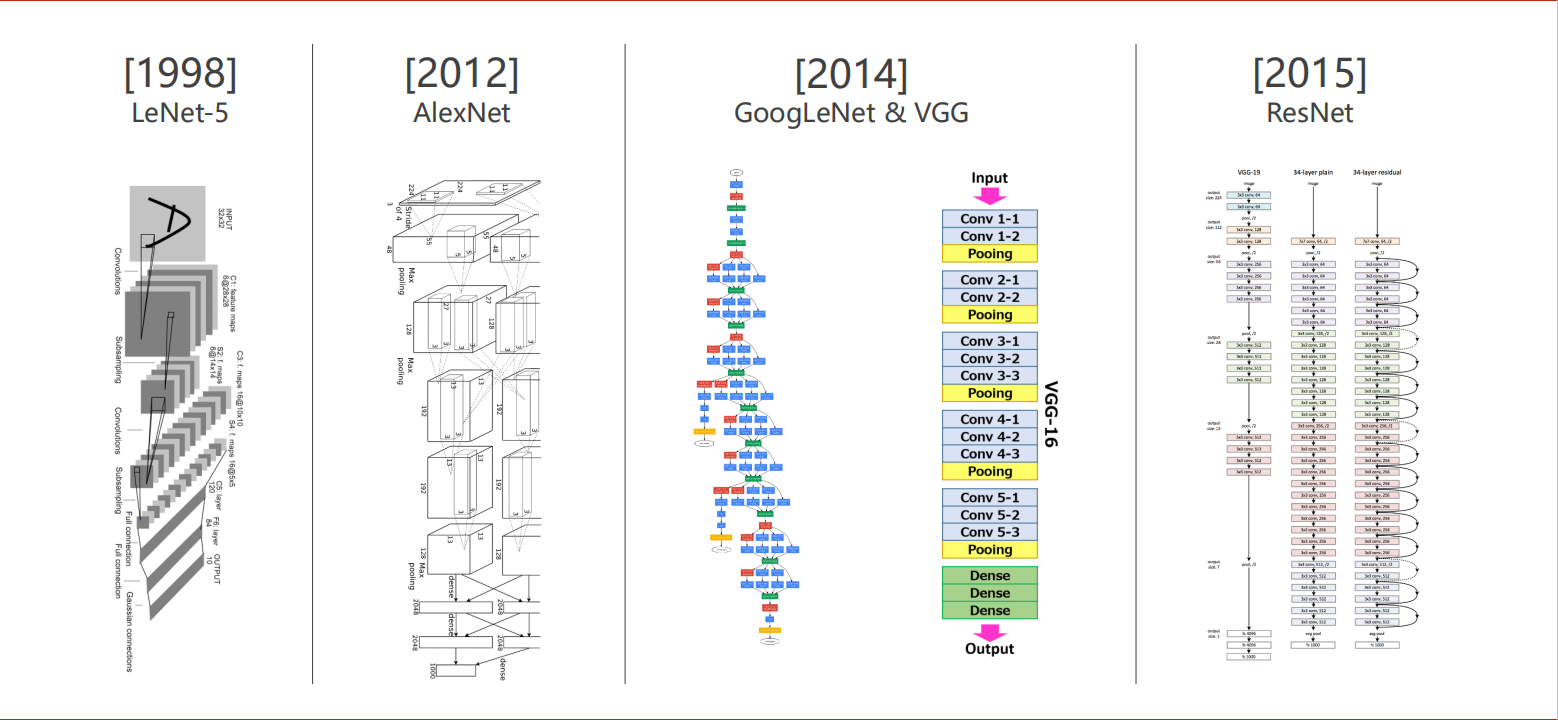
PyTorch深度学习实践Part1
PyTorch深度学习实践Part1——概论
技术成熟度曲线
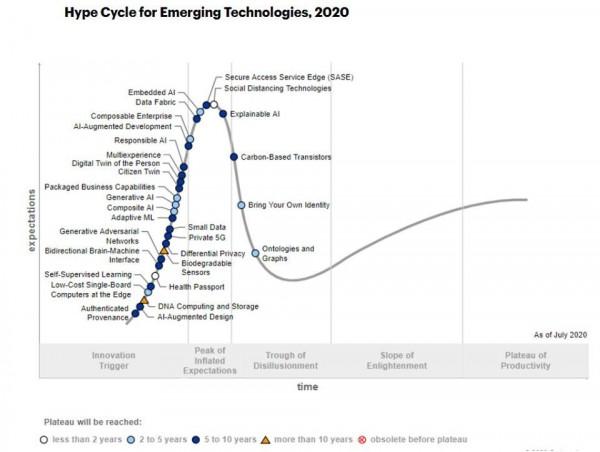
科技诞生的促动期 (Technology Trigger):在此阶段,随着媒体大肆的报道过度,非理性的渲染,产品的知名度无所不在,然而随着这个科技的缺点、问题、限制出现,失败的案例大于成功的案例,例如:.com公司 1998~2000年之间的非理性疯狂飙升期。
过高期望的峰值(Peak of Inflated Expectations):早期公众的过分关注演绎出了一系列成功的故事——当然同时也有众多失败的例子。对于失败,有些公司采取了补救措施,而大部分却无动于衷。
泡沫化的底谷期 (Trough of Disillusionment):在历经前面阶段所存活的科技经过多方扎实有重点的试验,而对此科技的适用范围及限制是以客观的并实际的了解,成功并能存活的经营模式逐渐成长。
稳步爬升的光明期 (Slope of Enlightenment):在此阶段,有一新科技的诞生,在市面上受到主要媒体与业界高度的注意,例如:1996年的Internet ,Web。
实质生产的高峰期 (Plateau of Productivity):在此阶段,新科技产生的利益与潜力被市场实际接受,实质支援此经营模式的工具、方法论经过数代的演进,进入了非常成熟的阶段。
在使用pytorch或一系列新技术的时候,一定要学会看官方文档,这是一个非常重要的能力!
人工智能
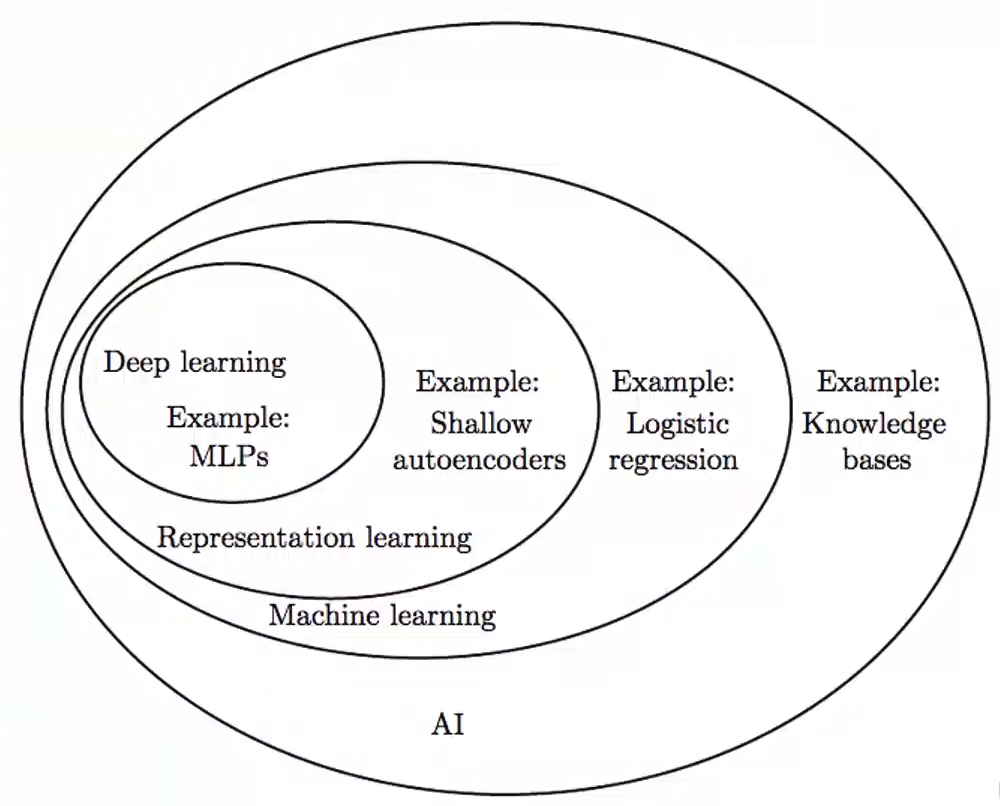
AI除了machine learning之外还有机器视觉、自然语言处理nlp、因果推断等。
机器学习大部分都是监督学习,即用一组标签过的值进行模型训练。
机器学习中的算法区别于普通的算法(穷举、贪心等),是通过数据训练并验证得出一个好用的模型,其计算过程来自于数据而不是人工的设计。
深度学习从模型上看用的是神经网络,从目标上看属于表示学习的分支。方法有,多层感知机、卷积神经网络、循环神经网络等。
维度诅咒
随着feature上升,为了保持准确性,其所需的数据量将急速上升,然而获取打过标签的数据,工作量大、成本高。
n1的向量采样点需要一个3n的矩阵来映射到3*1的向量,实现降维(PCA主成成分分析)。但是降维的同时也要尽量保证高维空间的度量信息,这个过程叫做表示学习(Present)。这个数据分布是在高维空间里的低维流行(Manifold)。
发展历史
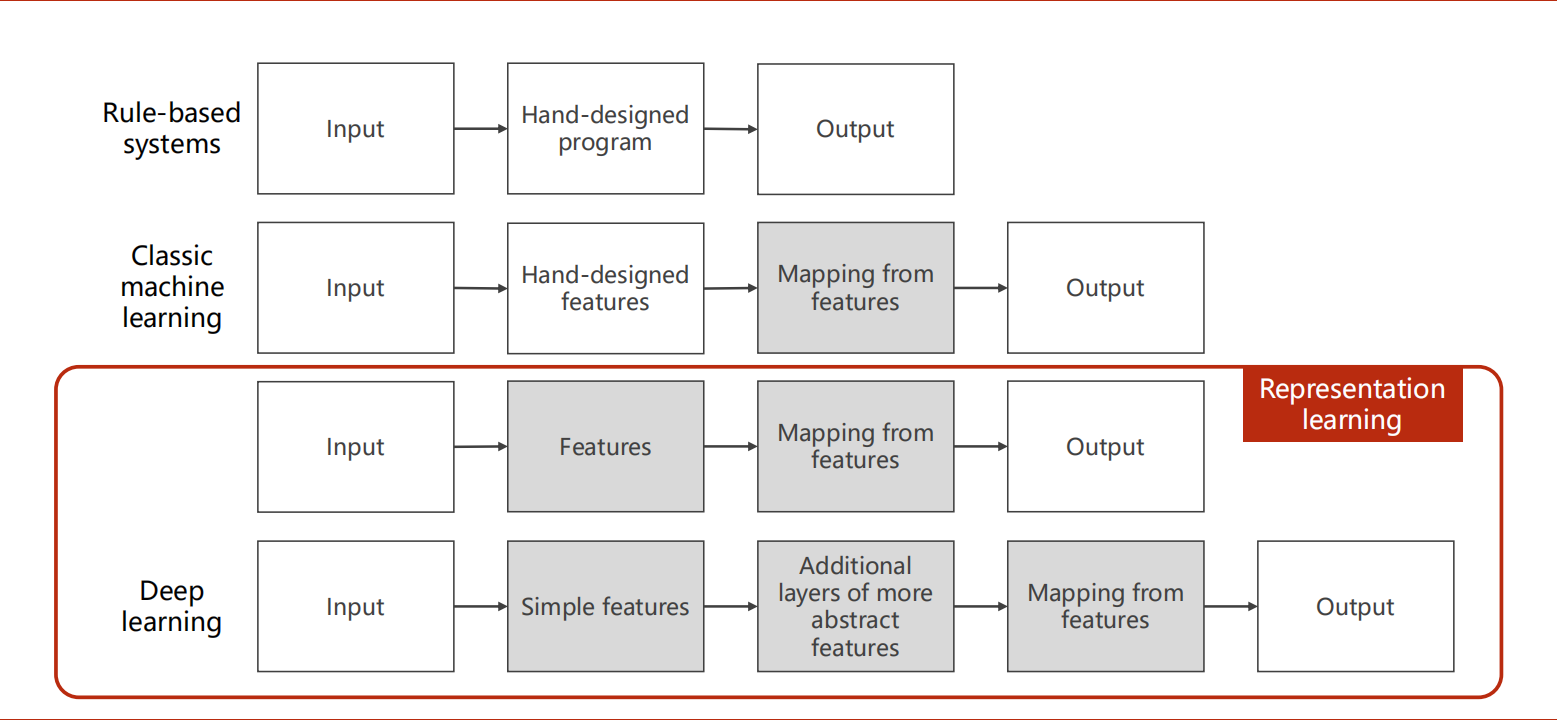
传统机器学习分类
神经网络发展
由生物实验得出,哺乳动物的视觉神经是分层的。浅层只检测物体的运动等,深层才开始识别物体的分类。由此出现了感知机。
现在神经网络早已不是生物的范畴,而是工程与数学方面。
真正让神经网络发展起来的是反向传播(Back Propagation),其核心在于计算图。