PyTorch-Part2
PyTorch-Part2——Pytorch 模型训练
[TOC]
数据(Data)
数据集划分
严谨的人工智能模型应用应当划分训练集(train set)、测试集(test set)和验证集(valid/dev set)三部分。
训练集就用来训练模型,测试集是用来估计模型在实际应用中的泛化能力,而验证集是用于模型选择和调参的。
在研究过程中,验证集和测试集作用都是一样的,只是对模型的泛化能力进行一个观测。
而当在工程应用中,由于尽可能地用尽所有数据集并迭代,要防止模型过拟合到测试集上,要有验证集对其进行约束。
可以使用
train : test : valid = 8 : 1 : 1这个比例。
PyTorch读取数据集
自定义数据集要继承
Dataset类,并重写__getitem__()和__len__()方法__init__():生成数据的路径列表,尤其对于非结构化数据集,不能直接将所有数据读入内存。__getitem__():由 DataLoader 进行调用,返回相应索引的数据,同时进行一系列的数据增强扩充数据集的多样性。__len__():提供数据集长度的查询。
读取数据流程:
在 MyDataset 中初始化图片路径和标签、数据增强方式
在 DataLoader 中初始化 num_workers、shuffle、batch_size、sampler、batch_sampler、collate_fn。即多进程读取数据、采样与拼接方法。
在 sampler 中会调用到 MyDataset 的
__len__()方法。在 iteration 进行时,DataLoder 才读取一个 batch 的图片数据。由 batch_sampler 与 collate_fn 确定一个 batch 的 indices 并进行拼接。
在 collate_fn 中会调用 MyDataset 类中的
__getitem__()方法。
在训练时,一般要对图片进行以下操作:
- 随机裁剪
- ToTensor:包含①[h, w, c] -> [c, h, w];② /255:归一化至 0~1 区间。
- 数据标准化(减均值,除以标准差)
1 | from PIL import Image |
transforms 的二十二个方法(干货)
- 裁剪——Crop
- 中心裁剪:
transforms.CenterCrop(size)- size- (sequence or int),若为 sequence,则为(h,w),若为 int,则(size,size)
- 随机裁剪:
transforms.RandomCrop(size, padding=None, pad_if_needed=False, fill=0, padding_mode='constant')- size- (sequence or int),若为 sequence,则为(h,w),若为 int,则(size,size)
- padding-(sequence or int, optional),当为 int时, 例如padding=a时,图片上下左右均填充a个像素;当为tupple时,(a, b),则左右填充a个像素,上下填充b个像素;(a, b, c, d), 则左填充a个像素,下填充b个像素,右填充c个像素, 上填充d个像素。
- fill- (int or tuple),填充的值(仅当padding_mode=’constant’)。int 时,各通道均填充该值,当长度为 3 的 tuple 时,表示 RGB 通道需要填充的值。
- padding_mode- 填充模式:1. constant,常量。2. edge,按照图片边缘的像素值来填充。3. reflect,镜像填充,最后一个像素不镜像。 4. symmetric,最后一个像素镜像。
- 随机长宽比裁剪:
transforms.RandomResizedCrop(size, scale=(0.08, 1.0), ratio=(0.75, 1.33), interpolation=2)- size- 所需裁剪图片尺寸。
- scale- 随机裁剪面积比例,默认scale=(0.08, 1.0),表示随机 crop 出来的图片会在的 0.08倍至 1 倍之间。
- ratio- 随机长宽比设置,默认(3/4, 4/3)
- interpolation- 插值的方法,默认为双线性插值(PIL.Image.BILINEAR)
- 上下左右中心裁剪:
transforms.FiveCrop(size)- size- (sequence or int),若为 sequence,则为(h,w),若为 int,则(size,size)
- 上下左右中心裁剪后翻转:
transforms.TenCrop(size, vertical_flip=False)- size- (sequence or int),若为 sequence,则为(h,w),若为 int,则(size,size)
- vertical_flip- (bool),是否垂直翻转,默认为 flase,即默认为水平翻转
- 中心裁剪:
- 翻转和旋转——Flip and Rotation
- 依概率 p 水平翻转:
transforms.RandomHorizontalFlip(p=0.5)- p- 概率,默认值为 0.5
- 依概率 p 垂直翻转:
transforms.RandomVerticalFlip(p=0.5)- p- 概率,默认值为 0.5
- 随机旋转:
transforms.RandomRotation(degrees, resample=False, expand=False, center=None)- degress- (sequence or float or int) ,若为 int,则在(-int,+int)之间随机旋转,若为 sequence,则在 s[0]~s[1] 度之间随机旋转
- resample- 重采样方法
- expand- 是否扩大图片,以保存图片原有信息
- center- 旋转中心,(0, 0)为左上角。默认为图片中心
- 依概率 p 水平翻转:
- 图像变换
- resize:
transforms.Resize(size, interpolation=2)- size- If size is an int, if height > width, then image will be rescaled to (size * height / width, size),所以建议 size 设定为 h*w
- interpolation- 插值方法选择,默认为 PIL.Image.BILINEAR
- 标准化:
transforms.Normalize(mean, std)- 对数据按通道进行标准化,即先减均值,再除以标准差,注意是 [h, w, c]
- 转为 tensor,并归一化至[0-1]:
transforms.ToTensor- 归一化至[0-1]是直接除以 255,若自己的 ndarray 数据尺度有变化,则需要自行修改。
- 填充图像边缘:
transforms.Pad(padding, fill=0, padding_mode='constant')- 同 随机裁剪 RandomCrop 的参数
- 修改亮度、对比度和饱和度:
transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0)- brightness- 亮度调整因子。当为a时,从 max((0, 1-a), 1+a) 中随机选择;当为(a, b)时,从[a, b]中随机选择。
- constant- 对比度参数,同brightness
- saturation- 饱和度参数,同brightness
- hue- 色相参数,当为a时,从[-a, a]中选择参数,注:0 <= a <= 0.5;当为(a, b)时,从[a, b]中选择参数,注:-0.5 <= a <= b <= 0.5
- 转灰度图:
transforms.Grayscale(num_output_channels=1)- num_output_channels- 输出通道数,只能设置1或者3
- 线性变换:
transforms.LinearTransformation(transformation_matrix)- 对矩阵做线性变化,可用于白化处理。 whitening: zero-center the data, compute the data covariance matrix
- 仿射变换:
transforms.RandomAffine(degrees, translate=None, scale=None, shear=None, resample=False, fillcolor=0)- degrees- 旋转角度设置
- translate- 平移区间设置如(a, b), a设置宽(width), b设置高(height) 。图像在宽维度的平移区间为 -img_width * a < dx < img_width * a
- scale- 缩放比例(以面积为单位)
- file_color- 填充颜色设置
- share- 错切角度设置,有水平错切和垂直错切,若为a,则仅在x轴错切,错切角度为(-a, a)之间;若为(a, b), 则a设置x轴角度,b设置y的角度;若为(a, b, c, d), 则a,b设置x轴度,c, d设置y角度
- resample- 重采样方式有NEAREST、BILINEAR、BICUBIC
- 依概率 p 转为灰度图:
transforms.RandomGrayscale(p=0.1)- p- 概率值,图像被转换为灰度图的概率
- 将数据转换为 PILImage:
transforms.ToPILImage(mode=None)- mode- 为 None 时,为 1 通道, mode=3 通道默认转换为 RGB,4 通道默认转换为 RGBA
- 随机遮挡:
transforms.RandomErasing(p=0.5, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=0, inplace=False)- p- 概率值
- scale- 遮挡区域与输入图像的比例范围
- ratio- 遮挡区域长宽比
- value- 设置遮挡区域的像素值,(R, G, B) or (Gray), value为字符串(不一定非要random)时,随机填充像素值。
- inplace- 改变自身
- transforms.Lambda:Apply a user-defined lambda as a transform
- resize:
- 对 transforms 操作,使数据增强更灵活
- transforms.RandomChoice(transforms),从给定的一系列 transforms 中选一个进行操作
- transforms.RandomApply(transforms, p=0.5),给一个 transform 加上概率,依概率进行操作
- transforms.RandomOrder,将 transforms 中的操作随机打乱
- 自定义 transforms
- 仅接收一个参数,返回一个参数
- 注意上下游的输出与输入
计算 Normalize 所用均值和方差
1 | import numpy as np |
模型(Model)
模型定义
- 三个要点
- 必须继承
nn.Module这个类,要让 PyTorch 知道这个类是一个 Module。 - 在
__init__(self)中设置好需要的隐藏层(如 conv、pooling、Linear、BatchNorm等)。 - 在
forward(self, x)中用定义好的网络结构进行组装,定义前馈过程。
- 必须继承
- 可以使用类似
_make_layer()类似的方法来辅助自定义网络层。
1 | from .BasicModule import BasicModule |
Sequential
- 可以用 list 或者 OrderedDict 进行网络的堆叠。
1 | # Example of using Sequential |
权值初始化
权值初始化流程
- 初始化流程
- 第一步,先设定什么层用什么初始化方法,初始化方法在 torch.nn.init 中给出;
- 第二步,实例化一个模型之后,执行该函数,即可完成初始化。
named_children()和named_modules()的区别:https://blog.csdn.net/watermelon1123/article/details/98036360
1 | # 定义权值初始化 |
权值初始化的十种方法(干货)
- Xavier 均匀分布:
torch.nn.init.xavier_uniform_(tensor, gain=1)- xavier 初始化方法中服从均匀分布 U(−a,a) ,分布的参数 a = gain * sqrt(6/fan_in+fan_out)。也称为 Glorot initialization。
- gain- 增益的大小是依据激活函数类型来设定。
- eg:nn.init.xavier_uniform_(w, gain=nn.init.calculate_gain(‘relu’))
- Xavier 正态分布:
torch.nn.init.xavier_normal_(tensor, gain=1)- xavier 初始化方法中服从正态分布,mean=0,std = gain * sqrt(2/fan_in + fan_out)
- kaiming 初始化方法,论文在《 Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification》,公式推导同样从“方差一致性”出法,kaiming是针对 xavier 初始化方法在 relu 这一类激活函数表现不佳而提出的改进,详细可以参看论文。
- kaiming 均匀分布:
torch.nn.init.kaiming_uniform_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')- 此为均匀分布,U~(-bound, bound), bound = sqrt(6/(1+a^2)*fan_in)。其中,a 为激活函数的负半轴的斜率,relu 是 0。
- mode- 可选为 fan_in 或 fan_out, fan_in 使正向传播时,方差一致; fan_out 使反向传播时,方差一致
- nonlinearity- 可选 relu 和 leaky_relu ,默认值为 。 leaky_relu
- eg:nn.init.kaiming_uniform_(w, mode=’fan_in’, nonlinearity=’relu’)
- kaiming 正态分布:
torch.nn.init.kaiming_normal_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')- 此为 0 均值的正态分布,N~ (0,std),其中 std = sqrt(2/(1+a^2)*fan_in)
- a- 激活函数的负半轴的斜率,relu 是 0
- mode- 可选为 fan_in 或 fan_out。fan_in 使正向传播时,方差一致;fan_out 使反向传播时,方差一致
- nonlinearity- 可选 relu 和 leaky_relu ,默认值为 leaky_relu。
- eg:nn.init.kaiming_normal_(w, mode=’fan_out’, nonlinearity=’relu’)
- 均匀分布初始化:
torch.nn.init.uniform_(tensor, a=0, b=1)- 使值服从均匀分布 U(a,b)
- 正态分布初始化:
torch.nn.init.normal_(tensor, mean=0, std=1)- 使值服从正态分布 N(mean, std),默认值为 0,1
- 常数初始化:
torch.nn.init.constant_(tensor, val)- 使值为常数 val nn.init.constant_(w, 0.3)
- 单位矩阵初始化:
torch.nn.init.eye_(tensor)- 将二维 tensor 初始化为单位矩阵(the identity matrix)
- 正交初始化:
torch.nn.init.orthogonal_(tensor, gain=1)- 使得 tensor 是正交的,论文:Exact solutions to the nonlinear dynamics of learning in deep linear neural networks” - Saxe, A. et al. (2013)
- 稀疏初始化:
torch.nn.init.sparse_(tensor, sparsity, std=0.01)- 从正态分布 N~(0. std)中进行稀疏化,使每一个 column 有一部分为 0
- sparsity- 每一个 column 稀疏的比例,即为 0 的比例
- eg:nn.init.sparse_(w, sparsity=0.1)
- 计算增益:
torch.nn.init.calculate_gain(nonlinearity, param=None)
其实,在创建网络实例的过程中, 一旦调用 nn.Conv2d 的时候就会有对权值进行初始化。
在 PyTorch1.0 版本后,Conv2d 改用了
kaiming_uniform_()进行初始化,可以在torch/nn/modules/conv.py中的 _ConvNd 类中的函数reset_parameters()中看到初始化方式。
模型加载与保存 Finetune
- 模型 Finetune 权值初始化:
- 保存模型,拥有一个预训练模型
- 加载模型,把预训练模型中的权值取出来
- 初始化,将网络的权重用预训练模型初始化
- 官方文档中介绍了两种保存模型的方法,一种是保存整个模型,另外一种是仅保存模型参数(官方推荐用这种方法)
1 | # 1. 创建 net |
不同层设置不同的学习率
- 在利用 pre-trained model 的参数做初始化之后,我们可能想让 fc 层更新相对快一些,而希望前面的权值更新小一些,这就可以通过为不同的层设置不同的学习率来达到此目的。
- 为不同层设置不同的学习率,主要通过优化器对多个参数组进行设置不同的参数。所以,只需要将原始的参数组,划分成两个,甚至更多的参数组,然后分别进行设置学习率。
- 这里将原始参数“切分”成 fc3 层参数和其余参数,为 fc3 层设置更大的学习率。
1 | lr_init: float = 0.001 |
- 挑选出特定的层的机制是利用内存地址作为过滤条件,将需要单独设定的部分参数从总的参数中剔除。
net.fc3.parameters()是一个<generator object parameters at 0x11b63bf00>ignored_params是包含 net.fc3 中 weight、bias 两者对应参数的内存地址列表base_params是一个 list,每个元素是一个 Parameter 类,其中剔除了 net.fc3 的 weight、bias
冻结权重与优化器仅传入部分参数两者是等价的。
个人认为:1. 用requires_grad=False会提高内存优化,因为不需要保存梯度。2. 仅传入优化器可以提高运行速度,因为不用对部分参数进行计算
损失函数(Loss Function)
PyTorch 的十七个损失函数(干货)
- 训练网络的过程,是不断优化网络权值使得损失函数值最小化的过程。
L1loss:
torch.nn.L1Loss(size_average=None, reduce=None)计算 output 和 target 之差的绝对值
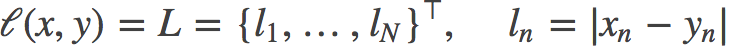
reduce(bool)- 返回值是否为标量,默认为 True
size_average(bool)- 当 reduce=True 时有效。为 True 时,返回的 loss 为平均值;为 False时,返回的各样本的 loss 之和
MSELoss:
torch.nn.MSELoss(size_average=None, reduce=None, reduction='elementwise_mean')计算 output 和 target 之差的平方
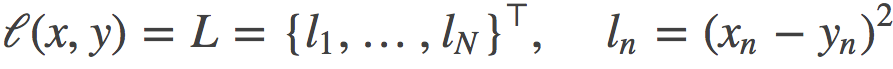
reduce(bool)- 返回值是否为标量,默认为 True
size_average(bool)- 当 reduce=True 时有效。为 True 时,返回的 loss 为平均值;为 False时,返回的各样本的 loss 之和
CrossEntropyLoss:
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='elementwise_mean')将输入经过 softmax 激活函数之后,再计算其与 target 的交叉熵损失。
该方法将 nn.LogSoftmax() 和 nn.NLLLoss() 进行了结合。严格意义上的交叉熵损失函数应该是 nn.NLLLoss()。
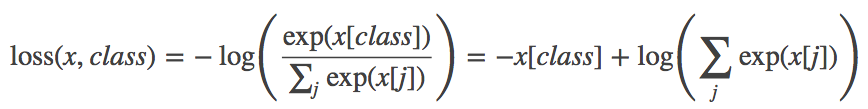
weight(Tensor)- 为每个类别的 loss 设置权值,常用于类别不均衡问题。weight 必须是 float类型的 tensor,其长度要于类别 C 一致,即每一个类别都要设置有 weight。
size_average(bool)- 当 reduce=True 时有效。为 True 时,返回的 loss 为平均值;为 False时,返回的各样本的 loss 之和。
reduce(bool)- 返回值是否为标量,默认为 True
ignore_index(int)- 忽略某一类别,不计算其 loss,其 loss 会为 0,并且,在采用size_average 时,不会计算那一类的 loss,除的时候的分母也不会统计那一类的样本。
NLLLoss:
torch.nn.NLLLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='elementwise_mean')不带 log_softmax 层的 CrossEntropyLoss 。
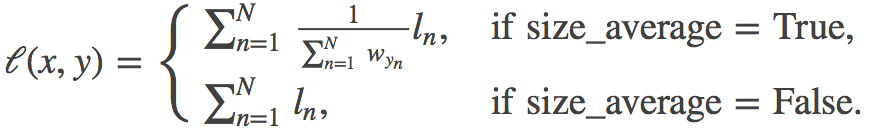
weight(Tensor)- 为每个类别的 loss 设置权值,常用于类别不均衡问题。weight 必须是 float类型的 tensor,其长度要于类别 C 一致,即每一个类别都要设置有 weight。
size_average(bool)- 当 reduce=True 时有效。为 True 时,返回的 loss 为除以权重之和的平均值;为 False 时,返回的各样本的 loss 之和。
reduce(bool)- 返回值是否为标量,默认为 True。
ignore_index(int)- 忽略某一类别,不计算其 loss,其 loss 会为 0,并且,在采用 size_average 时,不会计算那一类的 loss,除的时候的分母也不会统计那一类的样本。
PoissonNLLLoss:
torch.nn.PoissonNLLLoss(log_input=True, full=False, size_average=None, eps=1e-08, reduce=None, reduction='elementwise_mean')用于 target 服从泊松分布的分类任务。
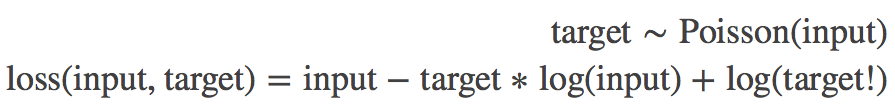
log_input(bool)- 为 True 时,计算公式为:loss(input,target)=exp(input) - target * input; 为 False 时,loss(input,target)=input - target * log(input+eps)
full(bool)- 是否计算全部的 loss。例如,当采用斯特林公式近似阶乘项时,此为 target*log(target) - target+0.5∗log(2πtarget)
eps(float)- 当 log_input = False 时,用来防止计算 log(0),而增加的一个修正项。即
loss(input,target)=input - target * log(input+eps)
size_average(bool)- 当 reduce=True 时有效。为 True 时,返回的 loss 为平均值;为 False时,返回的各样本的 loss 之和。
reduce(bool)- 返回值是否为标量,默认为 True
KLDivLoss:
torch.nn.KLDivLoss(size_average=None, reduce=None, reduction='elementwise_mean')计算 input 和 target 之间的 KL 散度( Kullback–Leibler divergence) 。又称为相对熵(Relative Entropy),用于描述两个概率分布之间的差异。
要想获得真正的 KL 散度,需要如下操作:1. reduce = True ;size_average=False;2. 计算得到的 loss 要对 batch 进行求平均
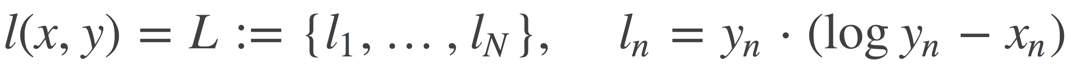
size_average(bool)- 当 reduce=True 时有效。为 True 时,返回的 loss 为平均值,平均值为
element-wise 的,而不是针对样本的平均;为 False 时,返回是各样本各维度的 loss 之和。
reduce(bool)- 返回值是否为标量,默认为 True。
BCELoss:
torch.nn.BCELoss(weight=None, size_average=None, reduce=None, reduction='elementwise_mean')二分类任务时的交叉熵计算函数。可以认为是 nn.CrossEntropyLoss 函数的特例。在 BCELoss 之前,input 一般为 sigmoid 激活层的输出。
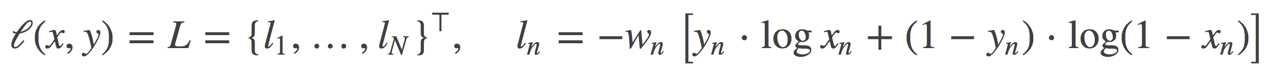
weight(Tensor)- 为每个类别的 loss 设置权值,常用于类别不均衡问题。
size_average(bool)- 当 reduce=True 时有效。为 True 时,返回的 loss 为平均值;为 False 时,返回的各样本的 loss 之和。
reduce(bool)- 返回值是否为标量,默认为 True
BCEWithLogitsLoss:
torch.nn.BCEWithLogitsLoss(weight=None, size_average=None, reduce=None, reduction='elementwise_mean', pos_weight=None)将 Sigmoid 与 BCELoss 结合,类似于 CrossEntropyLoss(将 nn.LogSoftmax()和 nn.NLLLoss() 进行结合)。即 input 会经过 Sigmoid 激活函数,将 input 变成概率分布的形式。
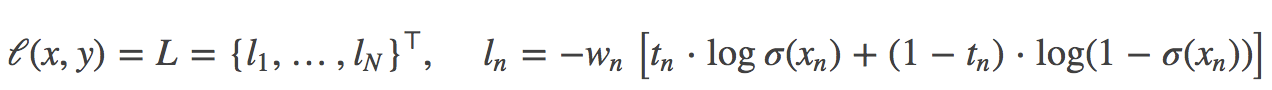
weight(Tensor)- : 为 batch 中单个样本设置权值,If given, has to be a Tensor of size “nbatch”.
pos_weight-: 正样本的权重, 当 p>1,提高召回率,当 P<1,提高精确度。可达到权衡召回率(Recall)和精确度(Precision)的作用。 Must be a vector with length equal to the number of classes.
size_average(bool)- 当 reduce=True 时有效。为 True 时,返回的 loss 为平均值;为 False 时,返回的各样本的 loss 之和。
reduce(bool)- 返回值是否为标量,默认为 True
MarginRankingLoss:
torch.nn.MarginRankingLoss(margin=0, size_average=None, reduce=None, reduction='elementwise_mean')计算两个向量之间的相似度,当两个向量之间的距离大于 margin,则 loss 为正,小于 margin,loss 为 0。
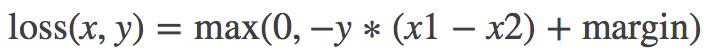
margin(float)- x1 和 x2 之间的差异。
size_average(bool)- 当 reduce=True 时有效。为 True 时,返回的 loss 为平均值;为 False时,返回的各样本的 loss 之和。
reduce(bool)- 返回值是否为标量,默认为 True。
HingeEmbeddingLoss:
torch.nn.HingeEmbeddingLoss(margin=1.0, size_average=None, reduce=None, reduction='elementwise_mean')为折页损失的拓展,主要用于衡量两个输入是否相似。used for learning nonlinear embeddings or semi-supervised
margin(float)- 默认值为 1,容忍的差距。
size_average(bool)- 当 reduce=True 时有效。为 True 时,返回的 loss 为平均值;为 False时,返回的各样本的 loss 之和。
reduce(bool)- 返回值是否为标量,默认为 True。
MultiLabelMarginLoss:
torch.nn.MultiLabelMarginLoss(size_average=None, reduce=None, reduction='elementwise_mean')用于一个样本属于多个类别时的分类任务。例如一个四分类任务,样本 x 属于第 0 类,第 1 类,不属于第 2 类,第 3 类。
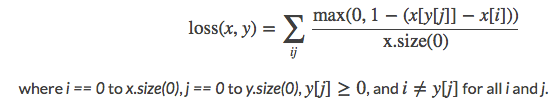
size_average(bool)- 当 reduce=True 时有效。为 True 时,返回的 loss 为平均值;为 False时,返回的各样本的 loss 之和。
reduce(bool)- 返回值是否为标量,默认为 True。
Input: (C) or (N,C) where N is the batch size and C is the number of classes.
Target: (C) or (N,C), same shape as the input.
SmoothL1Loss:
torch.nn.SmoothL1Loss(size_average=None, reduce=None, reduction='elementwise_mean')计算平滑 L1 损失,属于 Huber Loss 中的一种(因为参数 δ 固定为 1 了)。
Huber Loss 常用于回归问题,其最大的特点是对离群点(outliers)、噪声不敏感,具有较强的鲁棒性。
当误差绝对值小于 δ,采用 L2 损失;若大于 δ,采用 L1 损失。
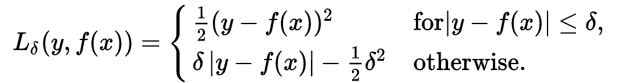
size_average(bool)- 当 reduce=True 时有效。为 True 时,返回的 loss 为平均值;为 False时,返回的各样本的 loss 之和。
reduce(bool)- 返回值是否为标量,默认为 True。
SoftMarginLoss:
torch.nn.SoftMarginLoss(size_average=None, reduce=None, reduction='elementwise_mean')Creates a criterion that optimizes a two-class classification logistic loss between input tensor x and target tensor y (containing 1 or -1).
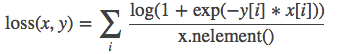
size_average(bool)- 当 reduce=True 时有效。为 True 时,返回的 loss 为平均值;为 False时,返回的各样本的 loss 之和。
reduce(bool)- 返回值是否为标量,默认为 True。
MultiLabelSoftMarginLoss:
torch.nn.MultiLabelSoftMarginLoss(weight=None, size_average=None, reduce=None, reduction='elementwise_mean')SoftMarginLoss 多标签版本,a multi-label one-versus-all loss based on max-entropy.
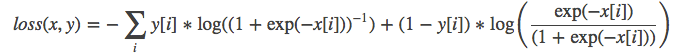
weight(Tensor)- 为每个类别的 loss 设置权值。weight 必须是 float 类型的 tensor,其长度要于类别 C 一致,即每一个类别都要设置有 weight。
CosineEmbeddingLoss:torch.nn.CosineEmbeddingLoss(margin=0, size_average=None, reduce=None, reduction=’elementwise_mean’)
用 Cosine 函数来衡量两个输入是否相似。 used for learning nonlinear embeddings or semi-supervised
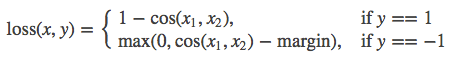
margin(float)- : 取值范围[-1,1], 推荐设置范围 [0, 0.5]
size_average(bool)- 当 reduce=True 时有效。为 True 时,返回的 loss 为平均值;为 False时,返回的各样本的 loss 之和。
reduce(bool)- 返回值是否为标量,默认为 True。
MultiMarginLoss:
torch.nn.MultiMarginLoss(p=1, margin=1, weight=None, size_average=None, reduce=None, reduction='elementwise_mean')计算多分类的折页损失。
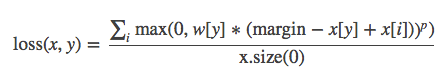
p(int)- 默认值为 1,仅可选 1 或者 2。
margin(float)- 默认值为 1
weight(Tensor)- 为每个类别的 loss 设置权值。weight 必须是 float 类型的 tensor,其长度要与类别 C 一致,即每一个类别都要设置有 weight。
size_average(bool)- 当 reduce=True 时有效。为 True 时,返回的 loss 为平均值;为 False时,返回的各样本的 loss 之和。
reduce(bool)- 返回值是否为标量,默认为 True。
TripletMarginLoss:torch.nn.TripletMarginLoss(margin=1.0, p=2, eps=1e-06, swap=False, size_average=None, reduce=None, reduction=’elementwise_mean’)
计算三元组损失,人脸验证中常用。
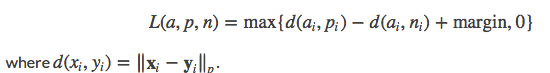
margin(float)- 默认值为 1
p(int)- The norm degree ,默认值为 2
swap(float)– The distance swap is described in detail in the paper Learning shallow convolutional
feature descriptors with triplet losses by V. Balntas, E. Riba et al. Default: False
size_average(bool)- 当 reduce=True 时有效。为 True 时,返回的 loss 为平均值;为 False时,返回的各样本的 loss 之和。
reduce(bool)- 返回值是否为标量,默认为 True。
优化器(Optimizer)
优化器类
- PyTorch 中所有的优化器均是 Optimizer 的子类。
参数组
- 参数组(param_groups)在 finetune、某层定制学习率、某层学习率置零等操作中,将发挥重要作用。
- optimizer 对参数的管理是基于组的概念,可以为每一组参数配置特定的 lr、momentum、weight_decay 等等。
- 参数组在 optimizer 中表现为一个 list(self.param_groups),其中每个元素是 dict,表示一个参数及其相应配置,在 dict 中包含’params’、’weight_decay’、’lr’ 、’momentum’等字段。
1 | w1 = torch.randn((2, 2), requires_grad=True) |
优化器常用方法
zero_grad():将梯度清零。- 由于 PyTorch 不会自动清零梯度,所以在每一次反向传播之前都应当进行此操作。
state_dict():将优化器的状态作为dict返回。返回 state、param_groups 组成的字典。- state - 保存当前优化状态的字典。 其内容优化器类之间有所不同。
param_groups - 包含所有参数组的字典
- state - 保存当前优化状态的字典。 其内容优化器类之间有所不同。
load_state_dict(state_dict):加载优化器状态。- 常用于 finetune。
add_param_group():给 optimizer 管理的参数组中增加一组参数。- 可为该组参数定制 lr、momentum、weight_decay 等,在 finetune 中常用。
step(closure):执行一步权值更新, 其中可传入参数 closure(一个闭包)。- 如,当采用 LBFGS 优化方法时,需要多次计算,因此需要传入一个闭包去允许它们重新计算 loss 。
PyTorch 的十个优化器(干货)
torch.optim.SGD:
torch.optim.SGD(params, lr=<object object>, momentum=0, dampening=0, weight_decay=0, nesterov=False)实现带动量的 SGD 优化算法,并且均可拥有 weight_decay 项。
params(iterable)- 参数组(参数组的概念请查看 3.2 优化器基类:Optimizer),优化器要管理的那部分参数。
lr(float)- 初始学习率,可按需随着训练过程不断调整学习率。
momentum(float)- 动量,通常设置为 0.9,0.8
dampening(float)- 若采用 nesterov,dampening 必须为 0.
weight_decay(float)- 权值衰减系数,也就是 L2 正则项的系数
nesterov(bool)- bool 选项,是否使用 NAG(Nesterov accelerated gradient)
torch.optim.ASGD:
torch.optim.ASGD(params, lr=0.01, lambd=0.0001, alpha=0.75, t0=1000000.0, weight_decay=0)ASGD 也称为 SAG,表示随机平均梯度下降(Averaged Stochastic Gradient Descent),简单地说 ASGD 就是用空间换时间的一种 SGD。
params(iterable)- 参数组(参数组的概念请查看 3.1 优化器基类:Optimizer),优化器要优化的那些参数。
lr(float)- 初始学习率,可按需随着训练过程不断调整学习率。
lambd(float)- 衰减项,默认值 1e-4。
alpha(float)- power for eta update ,默认值 0.75。
t0(float)- point at which to start averaging,默认值 1e6。
weight_decay(float)- 权值衰减系数,也就是 L2 正则项的系数。
torch.optim.Rprop:
torch.optim.Rprop(params, lr=0.01, etas=(0.5, 1.2), step_sizes=(1e-06, 50))实现 Rprop 优化方法(弹性反向传播),该优化方法适用于 full-batch,不适用于 mini-batch,因而在 mini-batch 大行其道的时代里,很少见到。
《Martin Riedmiller und Heinrich Braun: Rprop -A Fast Adaptive Learning Algorithm. Proceedings of the International Symposium on Computer and Information Science VII, 1992》
torch.optim.Adagrad:
torch.optim.Adagrad(params, lr=0.01, lr_decay=0, weight_decay=0, initial_accumulator_value=0)Adagrad(Adaptive Gradient) 是一种自适应优化方法,是自适应的为各个参数分配不同的学习率。这个学习率的变化,会受到梯度的大小和迭代次数的影响。梯度越大,学习率越小;梯度越小,学习率越大。缺点是训练后期,学习率过小,因为 Adagrad 累加之前所有的梯度平方作为分母。
torch.optim.Adadelta:
torch.optim.Adadelta(params, lr=1.0, rho=0.9, eps=1e-06, weight_decay=0)实现 Adadelta 优化方法。Adadelta 是 Adagrad 的改进。Adadelta 分母中采用距离当前时间点比较近的累计项,这可以避免在训练后期,学习率过小。
torch.optim.RMSprop:
torch.optim.RMSprop(params, lr=0.01, alpha=0.99, eps=1e-08, weight_decay=0, momentum=0, centered=False)实现 RMSprop 优化方法(Hinton 提出),RMS 是均方根(root meam square)的意思。RMSprop 和 Adadelta 一样,也是对 Adagrad 的一种改进。RMSprop 采用均方根作为分母,可缓解 Adagrad 学习率下降较快的问题,并且引入均方根,可以减少摆动
http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf
torch.optim.Adam(AMSGrad):
torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e- 08, weight_decay=0, amsgrad=False)实现 Adam(Adaptive Moment Estimation))优化方法。Adam 是一种自适应学习率的优化方法,Adam 利用梯度的一阶矩估计和二阶矩估计动态的调整学习率。吴老师课上说过,Adam 是结合了 Momentum 和 RMSprop,并进行了偏差修正。
amsgrad- 是否采用 AMSGrad 优化方法,asmgrad 优化方法是针对 Adam 的改进,通过添加额外的约束,使学习率始终为正值。
torch.optim.Adamax:
torch.optim.Adamax(params, lr=0.002, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)实现 Adamax 优化方法。Adamax 是对 Adam 增加了一个学习率上限的概念
torch.optim.SparseAdam:
torch.optim.SparseAdam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08)- 针对稀疏张量的一种“阉割版”Adam 优化方法。
torch.optim.LBFGS:
torch.optim.LBFGS(params, lr=1, max_iter=20, max_eval=None, tolerance_grad=1e-05, tolerance_change=1e-09, history_size=100, line_search_fn=None)- 实现 L-BFGS(Limited-memory Broyden–Fletcher–Goldfarb–Shanno)优化方法。L-BFGS 属于拟牛顿算法。L-BFGS 是对 BFGS 的改进,特点就是节省内存。
PyTorch 的六个学习率调整方法(干货)
StepLR:
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)等间隔调整学习率,调整倍数为 gamma 倍,调整间隔为 step_size。
间隔单位是 step。需要注意的是,step 通常是指 epoch,不要当成 iteration 。
step_size(int)- 学习率下降间隔数,若为 30,则会在 30、60、90……个 step 时,将学习率调整为 lr*gamma。
gamma(float)- 学习率调整倍数,默认为 0.1 倍,即下降 10 倍。
last_epoch(int)- 上一个 epoch 数,这个变量用来指示学习率是否需要调整。当 last_epoch 符合设定的间隔时,就会对学习率进行调整。当为 -1 时,学习率设置为初始值。
MultiStepLR:
torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)按设定的间隔调整学习率。这个方法适合后期调试使用,观察 loss 曲线,为每个实验定制学习率调整时机
milestones(list)- 一个 list,每一个元素代表何时调整学习率,list 元素必须是递增的。如 milestones=[30, 80, 120]
gamma(float)- 学习率调整倍数,默认为 0.1 倍,即下降 10 倍。
last_epoch(int)- 上一个 epoch 数,这个变量用来指示学习率是否需要调整。当 last_epoch 符合设定的间隔时,就会对学习率进行调整。当为 -1 时,学习率设置为初始值。
ExponentialLR:
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1)按指数衰减调整学习率,调整公式: lr = lr * gamma**epoch
gamma- 学习率调整倍数的底,指数为 epoch,即 gamma**epoch
last_epoch(int)- 上一个 epoch 数,这个变量用来指示学习率是否需要调整。当 last_epoch 符合设定的间隔时,就会对学习率进行调整。当为-1 时,学习率设置为初始值。
CosineAnnealingLR:
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1)余弦退火,以余弦函数为周期,并在每个周期最大值时重新设置学习率。
《SGDR: Stochastic Gradient Descent with Warm Restarts》(ICLR-2017)
T_max(int)- 一次学习率周期的迭代次数,即 T_max 个 epoch 之后重新设置学习率。
eta_min(float)- 最小学习率,即在一个周期中,学习率最小会下降到 eta_min,默认值为 0。
ReduceLROnPlateau:
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min',factor=0.1, patience=10, verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)检测指定的指标,当某指标不再变化(下降或升高)时,调整学习率。这是非常实用的学习率调整策略。
例如,当验证集的 loss 不再下降时,进行学习率调整;或者监测验证集的 accuracy,当 accuracy 不再上升时,则调整学习率。
mode(str)- 模式选择,有 min 和 max 两种模式,min 表示当指标不再降低(如监测loss),max 表示当指标不再升高(如监测 accuracy)。
factor(float)- 学习率调整倍数(等同于其它方法的 gamma),即学习率更新为 lr = lr * factor
patience(int)- “耐心”,即忍受该指标多少个 step 不变化,当忍无可忍时,调整学习率。
verbose(bool)- 是否打印学习率信息:print(‘Epoch {:5d}: reducing learning rate’ ‘ of group {} to {:.4e}.’.format(epoch, i, new_lr))
threshold(float)- Threshold for measuring the new optimum,配合 threshold_mode 使用。
threshold_mode(str)- 选择判断指标是否达最优的模式,有两种模式,rel 和 abs。 当 threshold_mode=rel,并且 mode=max 时,dynamic_threshold = best * ( 1 + threshold );
当 threshold_mode=rel,并且 mode=min 时,dynamic_threshold = best * ( 1 -threshold );
当 threshold_mode=abs,并且 mode=max 时,dynamic_threshold = best + threshold ;
当 threshold_mode=rel,并且 mode=max 时,dynamic_threshold = best - threshold
cooldown(int)- “冷却时间“,当调整学习率之后,让学习率调整策略冷静一下,让模型再训练一段时间,再重启监测模式。
min_lr(float or list)- 学习率下限,可为 float,或者 list,当有多个参数组时,可用 list 进行设置。
eps(float)- 学习率衰减的最小值,当学习率变化小于 eps 时,则不调整学习率。
LambdaLR:
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=- 1)为不同参数组自定义学习率调整策略。调整规则为,lr = base_lr * lmbda(self.last_epoch) 。
lr_lambda(function or list)- 一个计算学习率调整倍数的函数,输入通常为 step,当有多个参数组时,设为 list。
last_epoch(int)- 上一个 epoch 数,这个变量用来指示学习率是否需要调整。当 last_epoch 符合设定的间隔时,就会对学习率进行调整。当为-1 时,学习率设置为初始值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36model = resnet18(pretrained=False) # 加载模型
optimizer = torch.optim.SGD(params=[ # 初始化优化器,并设置两个param_groups
{'params': model.layer2.parameters()},
{'params': model.layer3.parameters(), 'lr': 0.2},
], lr=1, momentum=0.9, weight_decay=0.005) # base_lr = 0.1
epochs = 500 # 训练次数
warm_up_epoch = 5
t_max = epochs - warm_up_epoch # cos衰减周期
lr_max = 0.1 # 最大值
lr_min = 0.001 # 最小值
def get_warmup_cos_lambda(lr_max, lr_min, start, warm_up_epoch, t_max):
def warmup_cos_lambda(cur_epoch):
if cur_epoch < start:
return 0
elif cur_epoch < warm_up_epoch + start:
return (cur_epoch - start) / warm_up_epoch + lr_min
else:
return (lr_max - lr_min) * (1.0 + math.cos((cur_epoch - start - warm_up_epoch) / t_max * math.pi)) / 2 + lr_min
return warmup_cos_lambda
# LambdaLR
scheduler = torch.optim.lr_scheduler.LambdaLR(
optimizer,
lr_lambda=[
get_warmup_cos_lambda(lr_max, lr_min, 0, warm_up_epoch, t_max),
get_warmup_cos_lambda(lr_max, lr_min, 5, warm_up_epoch, t_max)
]
)
for epoch in range(epochs):
print(optimizer.param_groups[0]['lr'], optimizer.param_groups[1]['lr'])
optimizer.step()
scheduler.step()scheduler.step()
- 当调用
scheduler.step(epoch=None)时,如果不传入 epoch,默认成员变量 last_epoch+=1,如果传入 epoch,则直接更新 last_epoch。 - 因此,scheduler.step() 要放在 epoch 的 for 循环当中执行。当然也可以放在每个 batch 的 iter 中更新,这样更加细致。
- 更新完 last_epoch 之后,则调用
get_lr()获取当前 epoch 下,该参数组的学习率。
可视化
TensorBoardX
- 无法显示图表有可能是因为浏览器差异。
常用方法
在浏览器中查看可视化数据,只要在命令行中开启 tensorboard :
tensorboard --logdir=<your_log_dir>其中的
既可以是单个 run 的路径,也可以是多个 run 的父目录。如 runs/ 下面可能会有很多的子文件夹,每个文件夹都代表了一次实验,我们令 –logdir=runs/ 就可以在 tensorboard 可视化界面中方便地横向比较不同实验所得数据的差异。
SummaryWriter:
SummaryWriter(logdir=None, comment="", purge_step=None, max_queue=10, flush_secs=120, filename_suffix='', write_to_disk=True, log_dir=None, comet_config={"disabled": True}, **kwargs)创建一个 SummaryWriter 的实例
logdir- 用该路径来保存日志。无参数,默认将使用 runs/日期时间
comment- 文件夹后缀,将使用 runs/日期时间-comment 路径来保存日志
filename_suffix- 设置 event file 文件名后缀
```python
writer = SummaryWriter(log_dir=’./tensorboard event file’, filename_suffix=str(cfg.EPOCH_NUMBER), comment=’test_tensorboard’)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2. add_scalar:`add_scalar(tag, scalar_value, global_step=None, walltime=None)`
- 在一个图表中记录一个标量的变化,常用于 loss、accuracy、learning rate 曲线的记录。
- **tag**(string)- 该图的标签,类似于 polt.title
**scalar_value**(float or string/blobname)- 用于存储的值,曲线图的 y 坐标。注意,对于 PyTorch scalar tensor,需要调用 `.item()` 方法获取其数值
**global_step**(int)- 曲线图的 x 坐标
**walltime**(float)- 为 event 文件的文件名设置时间,默认为 time.time()
- ```python
writer.add_scalar('Train Loss', train_loss / num_mini_batch, epoch)
add_scalars:
add_scalars(main_tag, tag_scalar_dict, global_step=None, walltime=None)在一个图表中记录多个标量的变化,常用于对比,如 trainLoss 和 validLoss 的比较等。
main_tag(string)- 该图的标签。
tag_scalar_dict(dict)- key 是变量的 tag,value 是变量的值。
global_step(int)- 曲线图的 x 坐标
walltime(float)- 为 event 文件的文件名设置时间,默认为 time.time()
writer.add_scalars('data/scalar_group', {"xsinx": x * np.sin(x), "xcosx": x * np.cos(x), "arctanx": np.arctan(x)}, x)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
4. add_histogram:`add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None)`
- 绘制直方图和多分位数折线图,常用于监测权值及梯度的分布变化情况,便于诊断网络更新方向是否正确。
- **tag**(string)- 该图的标签,类似于 polt.title。
**values**(torch.Tensor, numpy.array or string/blobname)- 用于绘制直方图的值
**global_step**(int)- 曲线图的 y 坐标
**bins**(string)- 决定如何取 bins,默认为‘tensorflow’,可选:’auto’, ‘fd’等
**walltime**(float)- 为 event 文件的文件名设置时间,默认为 time.time()
5. add_image:`add_image(tag, img_tensor, global_step=None, walltime=None)`
- 绘制图片,可用于检查模型的输入,监测 feature map 的变化,或是观察 weight。
- **tag**(string)- 该图的标签,类似于 polt.title。
**img_tensor**(torch.Tensor,numpy.array, or string/blobname)- 需要可视化的图片数据, shape = [C,H,W]。
**global_step**(int)- x 坐标。
**walltime**(float)- 为 event 文件的文件名设置时间,默认为 time.time()。
- 通常会借助 torchvision.utils.make_grid() 将一组图片绘制到一个窗口
- torchvision.utils.make_grid:`torchvision.utils.make_grid(tensor, nrow=8, padding=2, normalize=False, range=None, scale_each=False, pad_value=0)`
- 将一组图片拼接成一张图片,便于可视化。
- **tensor**(Tensor or list)- 需可视化的数据,shape:(B x C x H x W) ,B 表示 batch 数,即几张图片
**nrow**(int)- 一行显示几张图,默认值为 8。
**padding**(int)- 每张图片之间的间隔,默认值为 2。
**normalize**(bool)- 是否进行归一化至(0,1)。
**range**(tuple)- 设置归一化的 min 和 max,若不设置,默认从 tensor 中找 min 和 max。
**scale_each**(bool)- 每张图片是否单独进行归一化,还是 min 和 max 的一个选择。
**pad_value**(float)- 填充部分的像素值,默认为 0,即黑色。
6. add_graph:`add_graph(model, input_to_model=None, verbose=False, **kwargs)`
- 绘制网络结构拓扑图。
- **model**(torch.nn.Module)- 模型实例
**inpjt_to_model**(torch.autograd.Variable)- 模型的输入数据,可以生成一个随机数,只要 shape 符合要求即可
- ```python
init_img = torch.zeros((1, 3, 400, 400), device=device)
init_msg = torch.zeros((1, secret_size), device=device)
tb_writer.add_graph(StegaStampEncoder, {"img": init_img, "msg": init_msg})另外一种用于 debug 检查模型的方法:summary() 可输出模型每层输入输出的 shape 以及模型总量。使用前需要在终端 pip install torchsummary。
from torchsummary import summary print(summary(net, (3, 360, 640), device="cpu"))#### 特征图可视化1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
7. add_embedding:`add_embedding(mat, metadata=None, label_img=None, global_step=None, tag='default', metadata_header=None)`
- 在三维空间或二维空间展示数据分布,可选 T-SNE、PCA 和 CUSTOM 方法。
- **mat**(torch.Tensor or numpy.array)- 需要绘制的数据,一个样本必须是一个向量形式。
**shape** = (N,D),N 是样本数,D 是特征维数。
**metadata**(list)- 数据的标签,是一个 list,长度为 N。
**label_img**(torch.Tensor)- 空间中展示的图片,shape = (N,C,H,W)。
**global_step**(int)- Global step value to record,不理解这里有何用处呢?知道的朋友补充一下吧。
**tag**(string)- 标签
8. add_text:`add_text(tag, text_string, global_step=None, walltime=None)`
- 记录文字
9. add_video:`add_video(tag, vid_tensor, global_step=None, fps=4, walltime=None)`
- 记录 video
10. add_figure:`add_figure(tag, figure, global_step=None, close=True, walltime=None)`
- 添加 matplotlib 图片到图像中
11. add_image_with_boxes:`add_image_with_boxes(tag, img_tensor, box_tensor, global_step=None, walltime=None, **kwargs)`
- 图像中绘制 Box,目标检测中会用到
12. add_pr_curve:`add_pr_curve(tag, labels, predictions, global_step=None, num_thresholds=127, weights=None, walltime=None)`
- 绘制 PR 曲线
13. add_pr_curve_raw:`add_pr_curve_raw(tag, true_positive_counts, false_positive_counts, true_negative_counts, false_negative_counts, precision, recall, global_step=None, num_thresholds=127, weights=None, walltime=None)`
- 从原始数据上绘制 PR 曲线
14. export_scalars_to_json:`export_scalars_to_json(path)`
- 将 scalars 信息保存到 json 文件,便于后期使用
#### 卷积核可视化
- 神经网络中最重要的就是权值,而人们对神经网络理解有限,所以我们需要通过尽可能了解权值来帮助诊断网络的训练情况。除了查看权值分布图和多折线分位图,还可以对卷积核权值进行可视化,来辅助我们分析网络。对卷积核权值进行可视化,在一定程度上帮助我们诊断网络的训练好坏,因此对卷积核权值的可视化十分有必要。
- 可视化原理很简单,对单个卷积核进行“归一化”至 0~255,然后将其展现出来即可,这一系列操作可以借助 TensorboardX 的 add_image 来实现。
- 决定一张特征图需要的卷积核的维度由输入通道决定,生成的特征图数量由卷积核的数量决定。
```python
import os
import torch
import torchvision.utils as vutils
from tensorboardX import SummaryWriter
import torch.nn as nn
import torch.nn.functional as F
net = Net() # 创建一个网络
pretrained_dict = torch.load(os.path.join("..", "2_model", "net_params.pkl"))
net.load_state_dict(pretrained_dict)
writer = SummaryWriter(log_dir=os.path.join("..", ".." "Result", "visual_weights"))
params = net.state_dict()
for k, v in params.items():
if 'conv' in k and 'weight' in k:
c_int = v.size()[1] # 输入层通道数
c_out = v.size()[0] # 输出层通道数
# 以feature map为单位,绘制一组卷积核,一张feature map对应的卷积核个数为输入通道数
for j in range(c_out):
print(k, v.size(), j)
kernel_j = v[j, :, :, :].unsqueeze(1) # 压缩维度,为make_grid制作输入
kernel_grid = vutils.make_grid(kernel_j, normalize=True, scale_each=True, nrow=c_int) # 1*输入通道数, w, h
writer.add_image(k + '_split_in_channel', kernel_grid, global_step=j) # j 表示feature map数
# 将一个卷积层的卷积核绘制在一起,每一行是一个 feature map 的卷积核
k_w, k_h = v.size()[-1], v.size()[-2]
kernel_all = v.view(-1, 1, k_w, k_h)
kernel_grid = vutils.make_grid(kernel_all, normalize=True, scale_each=True, nrow=c_int) # 1*输入通道数, w, h
writer.add_image(k + '_all', kernel_grid, global_step=666)
writer.close()
获取图片,将其转换成模型输入前的数据格式,即一系列 transform,
获取模型各层操作,手动的执行每一层操作,拿到所需的 feature maps,
借助 tensorboardX 进行绘制。
1 | import os |
梯度及权值分布可视化
代码实现
- 在网络训练过程中,我们常常会遇到梯度消失、梯度爆炸等问题,我们可以通过记录每个 epoch 的梯度的值来监测梯度的情况,还可以记录权值,分析权值更新的方向是否符合规律。
1 | import torch |
可视化分析
权值 weights 的监控
经过 100 个 epoch 的训练,来看看第一个卷积层的权值分布的变化。x 轴即变量大小,y 轴为 gloabl_step。
图 1 x=0.306, y=0, 数值显示为 0.00,表示第 0 个 epoch 时,权值为 0.306 的个数为 0.00。
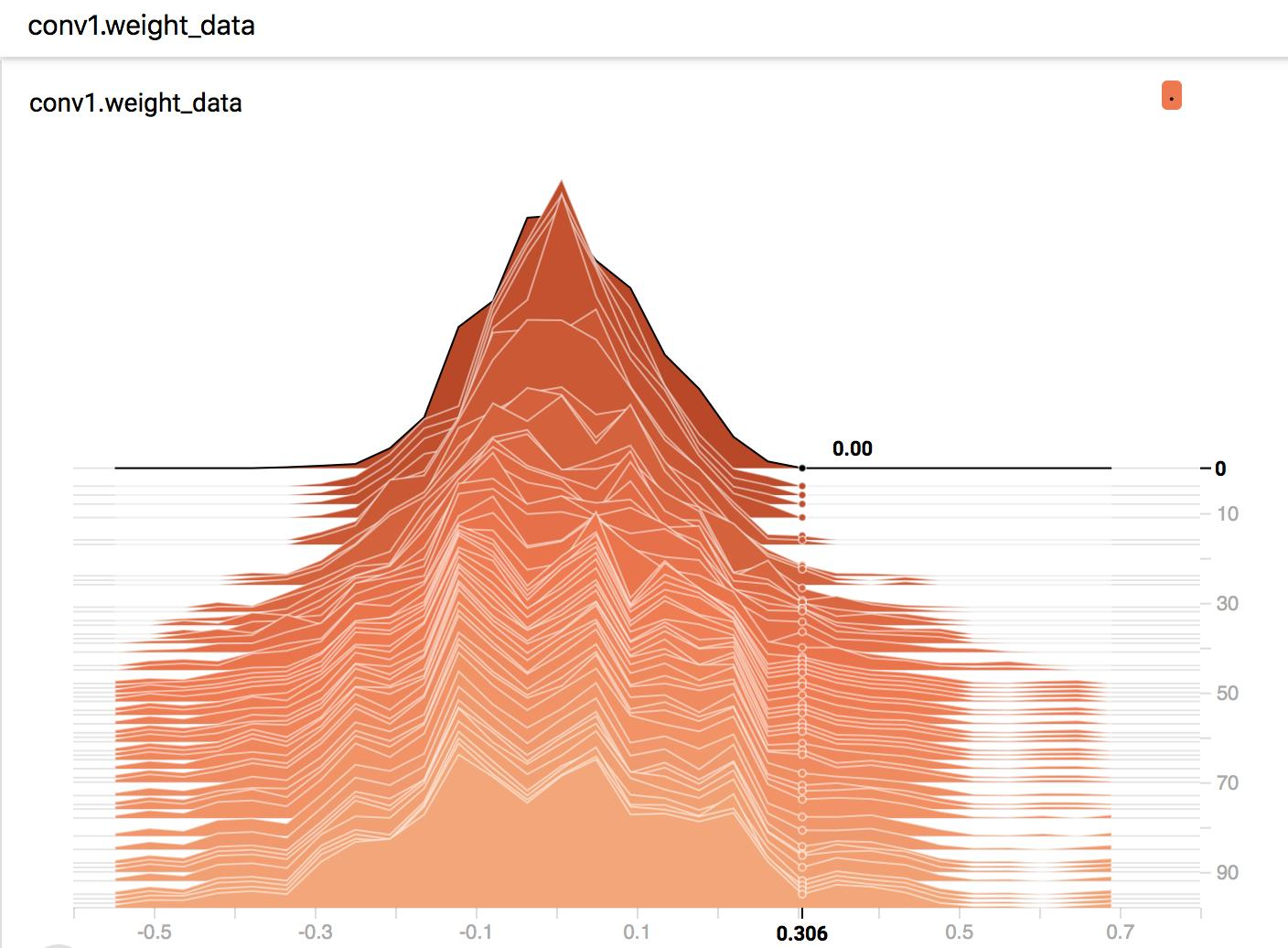
图 2, x=0.306, y=85, 数值显示为 5.71,表示第 85 个 epoch 时,权值在 0.306 区间的有 5.71 个。
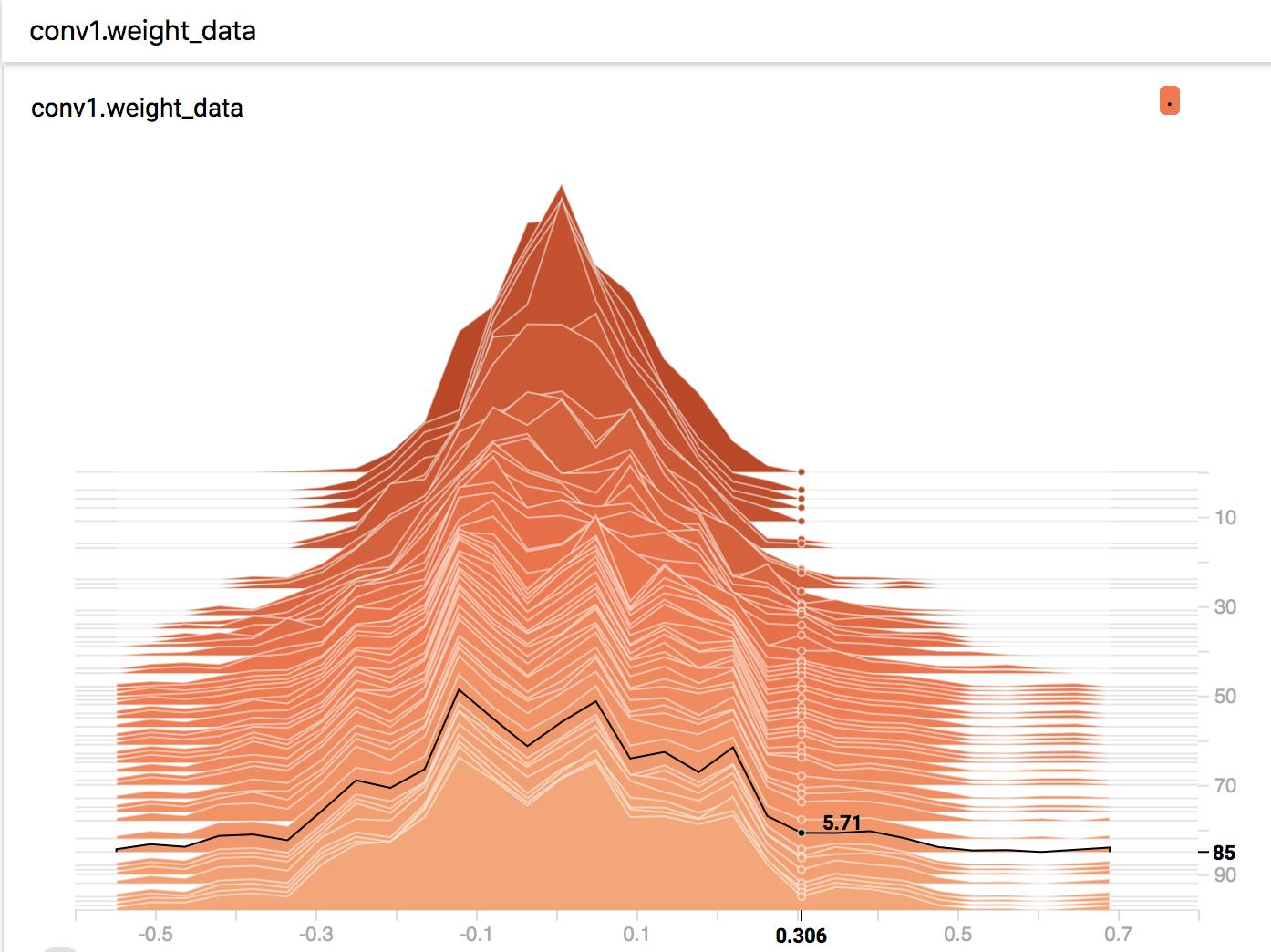
通过 HISTOGRAMS 可以看到第一个卷积层的权值随着训练的不断的“扩散”,一开始是个比较标准的高斯分布,并且最大值不会超过 0.3。
而到了后期,权值会发散到 0.6+,这个问题也是需要关注的,若权值太大容易导致过拟合。因为模型的输出值会被该特征所主导,从而引起过拟合现象,这个可以通过权值衰减(weight_decay)来缓解。
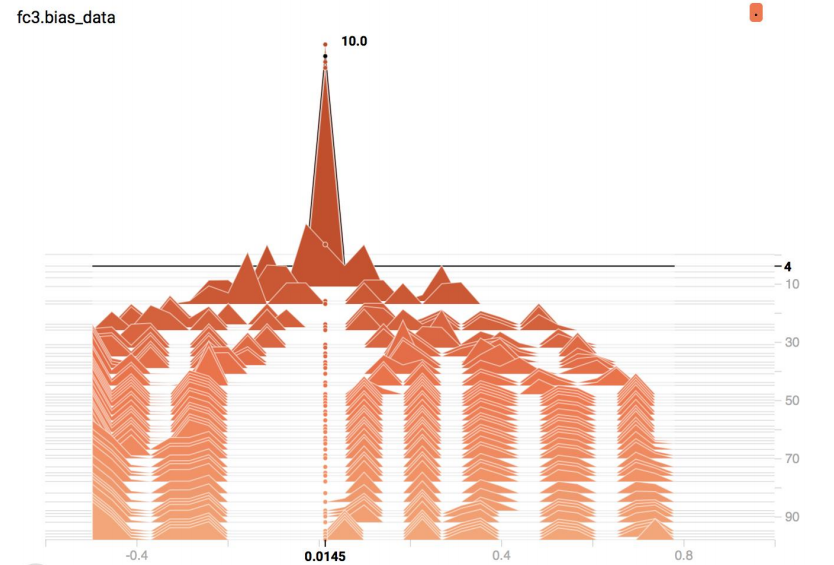
偏置 bias 的监控
通常会监控输出层的 bias 的大小,若有特别大,或者特别小的 bias,那么某一类别的召回率可能会很低,可以通过观察输出层的 bias 来诊断是否在这一环节出问题。
从图上可以看到,一开始 10 个类别的 bias 都比较小,随着训练的进行,每个类别都有了自己的固定的 bias 大小。
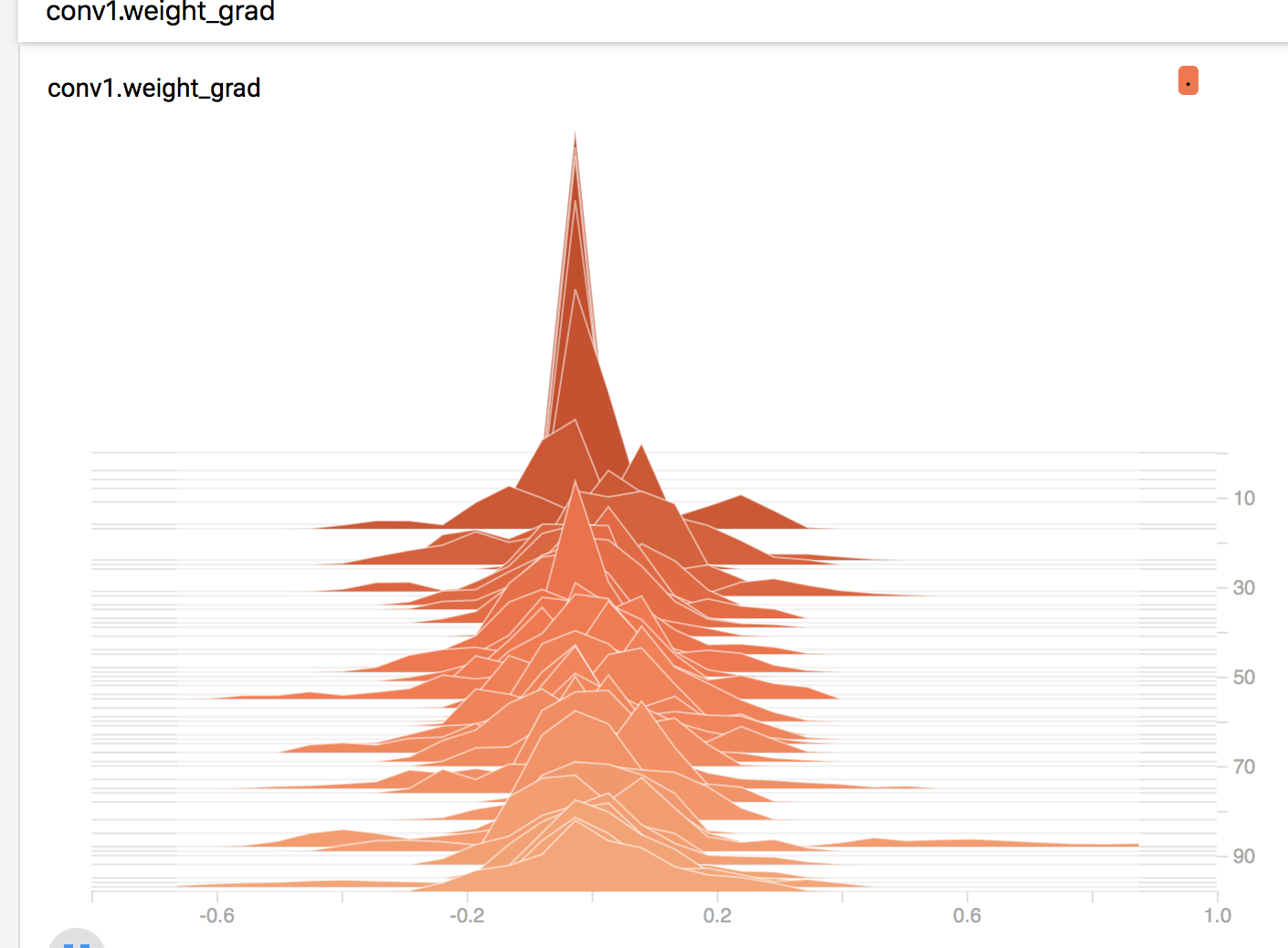
梯度的监控
下图为第一个卷积层权值的梯度变化情况,可以看到,几乎都是服从高斯分布的。倘若前面几层的梯度非常小,那么就是梯度流通不畅导致的,可以考虑残差结构或者辅助损失层等 trick 来解决梯度消失。
文末思考:
通过观察各层的梯度,权值分布,我们可以针对性的设置学习率,为那些梯度小的层设置更大的学习率,让那些层可以有效的更新。
对权值特别大的那些层,可以考虑为那一层设置更大的 weight_decay,是否能有效降低该层权值大小呢。
通过对梯度的观察,可以合理的设置梯度 clip 的值。
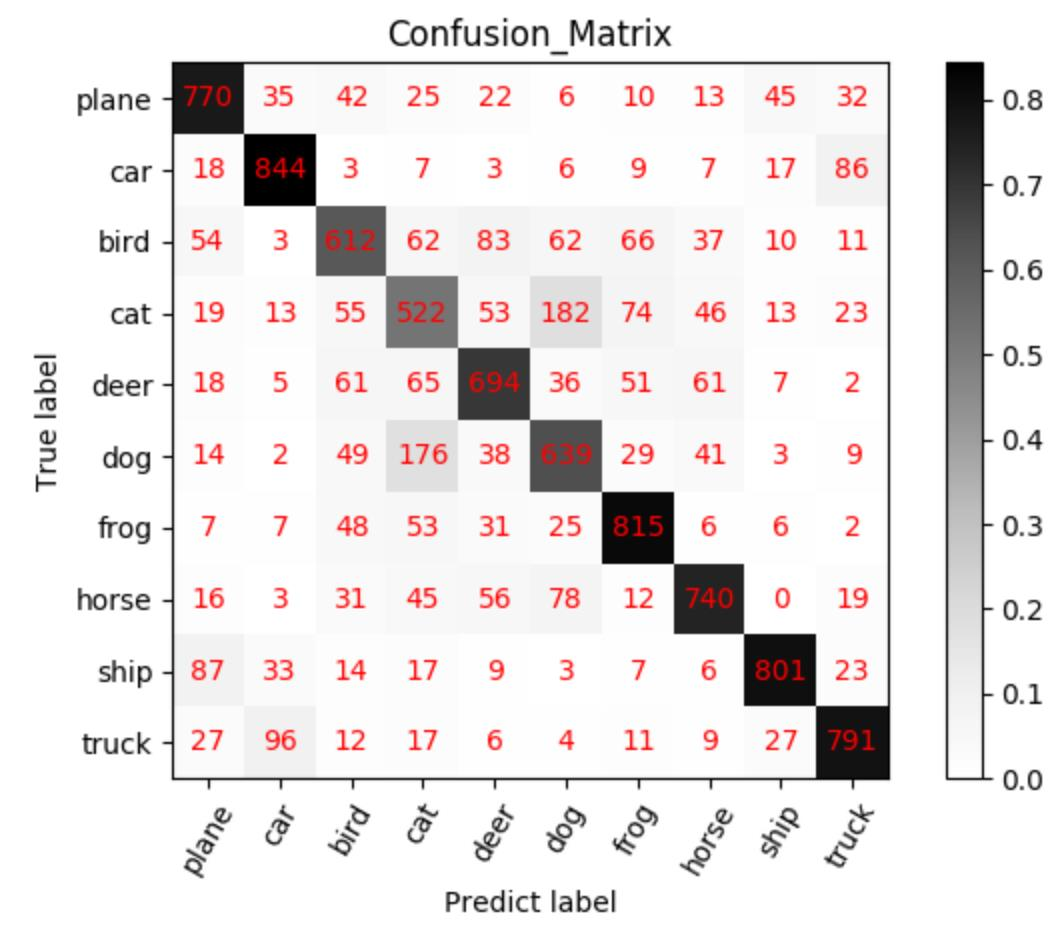
混淆矩阵及其可视化
混淆矩阵(Confusion Matrix)常用来观察分类结果,其是一个 N*N 的方阵,N 表示类别数。混淆矩阵的行表示真实类别,列表示预测类别。
1 | def show_confMat(confusion_mat, classes_name, set_name, out_dir): |