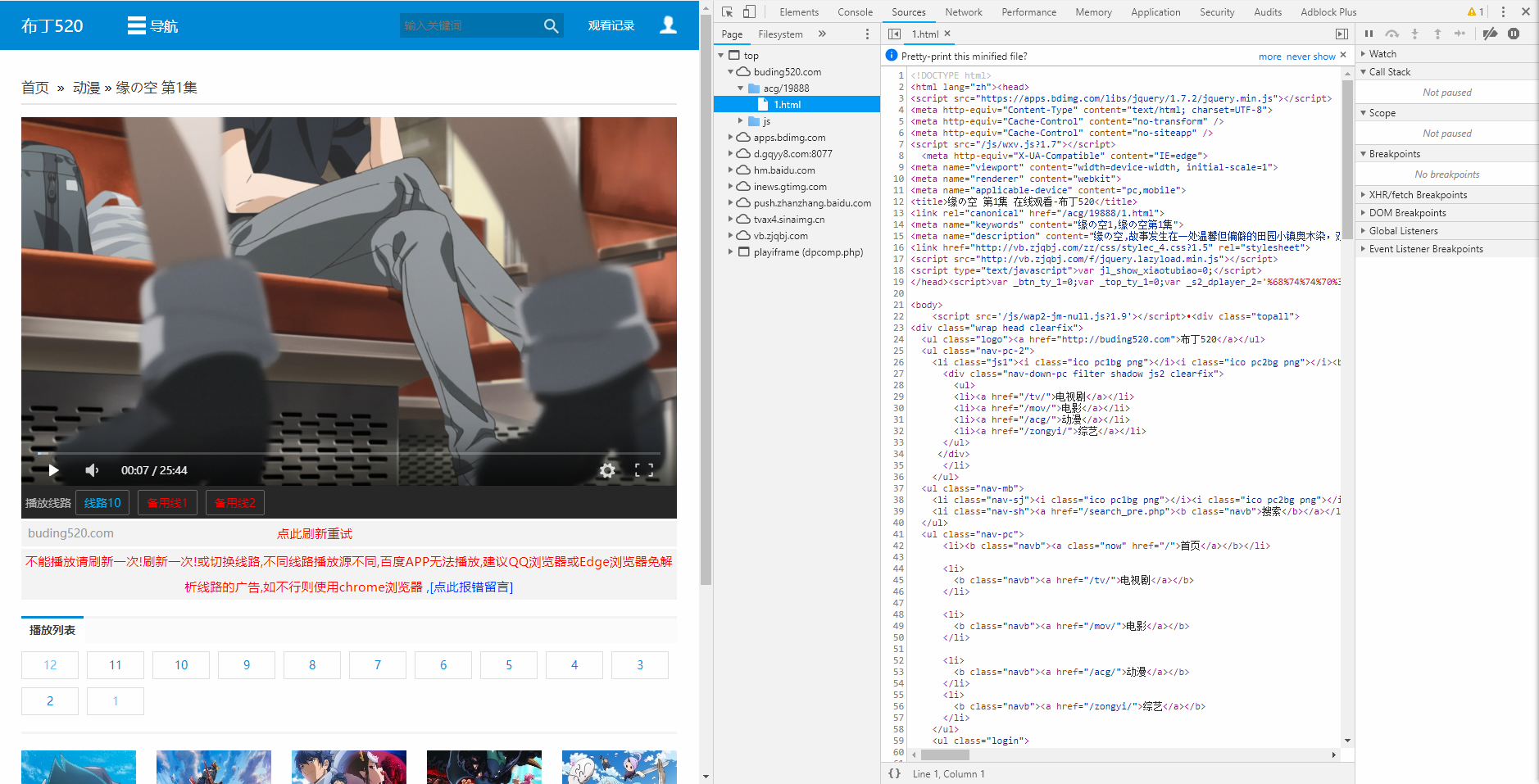
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
| """
思路:
1. 拿到主页面的页面源代码, 找到iframe
2. 从iframe的页面源代码中拿到m3u8文件的地址
3. 下载第一层m3u8文件 -> 下载第二层m3u8文件(视频存放路径)
4. 下载ts切片视频(协程)
5. 下载秘钥, 进行解密操作(协程)
6. 合并所有ts文件为一个mp4文件
"""
import requests
from bs4 import BeautifulSoup
import re
import asyncio
import aiohttp
import aiofiles
from Crypto.Cipher import AES
import os
def get_iframe_src(url):
resp = requests.get(url)
main_page = BeautifulSoup(resp.text, "html.parser")
src = main_page.find("iframe").get("src")
return src
def get_first_m3u8_url(url):
resp = requests.get(url)
obj = re.compile(r'var main = "(?P<m3u8_url>.*?)"', re.S)
m3u8_url = obj.search(resp.text).group("m3u8_url")
return m3u8_url
def download_m3u8_file(url, name):
resp = requests.get(url)
with open(name, mode="wb") as f:
f.write(resp.content)
async def download_ts(url, name, session):
async with session.get(url) as resp:
async with aiofiles.open(f"video2/{name}", mode="wb") as f:
await f.write(await resp.content.read())
print(f"{name}下载完毕")
async def aio_download(up_url):
tasks = []
async with aiohttp.ClientSession() as session:
async with aiofiles.open("越狱第一季第一集_second_m3u8.txt", mode="r", encoding='utf-8') as f:
async for line in f:
if line.startswith("#"):
continue
line = line.strip()
ts_url = up_url + line
task = asyncio.create_task(download_ts(ts_url, line, session))
tasks.append(task)
await asyncio.wait(tasks)
def get_key(url):
resp = requests.get(url)
return resp.text
async def dec_ts(name, key):
aes = AES.new(key=key, IV=b"0000000000000000", mode=AES.MODE_CBC)
async with aiofiles.open(f"video2/{name}", mode="rb") as f1, \
aiofiles.open(f"video2/temp_{name}", mode="wb") as f2:
bs = await f1.read()
await f2.write(aes.decrypt(bs))
print(f"{name}处理完毕")
async def aio_dec(key):
tasks = []
async with aiofiles.open("越狱第一季第一集_second_m3u8.txt", mode="r", encoding="utf-8") as f:
async for line in f:
if line.startswith("#"):
continue
line = line.strip()
task = asyncio.create_task(dec_ts(line, key))
tasks.append(task)
await asyncio.wait(tasks)
def merge_ts():
lst = []
with open("越狱第一季第一集_second_m3u8.txt", mode="r", encoding="utf-8") as f:
for line in f:
if line.startswith("#"):
continue
line = line.strip()
lst.append(f"video2/temp_{line}")
s = "+".join(lst)
os.system(f"copy /b {s} movie.mp4")
print("done!")
def main(url):
iframe_src = get_iframe_src(url)
first_m3u8_url = get_first_m3u8_url(iframe_src)
iframe_domain = iframe_src.split("/share")[0]
first_m3u8_url = iframe_domain + first_m3u8_url
download_m3u8_file(first_m3u8_url, "越狱第一季第一集_first_m3u8.txt")
with open("越狱第一季第一集_first_m3u8.txt", mode="r", encoding="utf-8") as f:
for line in f:
if line.startswith("#"):
continue
else:
line = line.strip()
second_m3u8_url = first_m3u8_url.split("index.m3u8")[0] + line
download_m3u8_file(second_m3u8_url, "越狱第一季第一集_second_m3u8.txt")
print("m3u8文件下载完毕")
second_m3u8_url_up = second_m3u8_url.replace("index.m3u8", "")
asyncio.run(aio_download(second_m3u8_url_up))
key_url = second_m3u8_url_up + "key.key"
key = get_key(key_url)
asyncio.run(aio_dec(key))
merge_ts()
if __name__ == '__main__':
url = "https://www.91kanju.com/vod-play/541-2-1.html"
main(url)
|