爬虫Part3——Requests进阶
[TOC]
Requests进阶概述
HTTP协议中的请求头header,⼀般会包含安全验证信息,比如常见的User-Agent, token, cookie等。
- 模拟浏览器登录 -> 处理cookie
- 防盗链处理 -> 抓取梨视频数据
- 代理 -> 防⽌被封IP
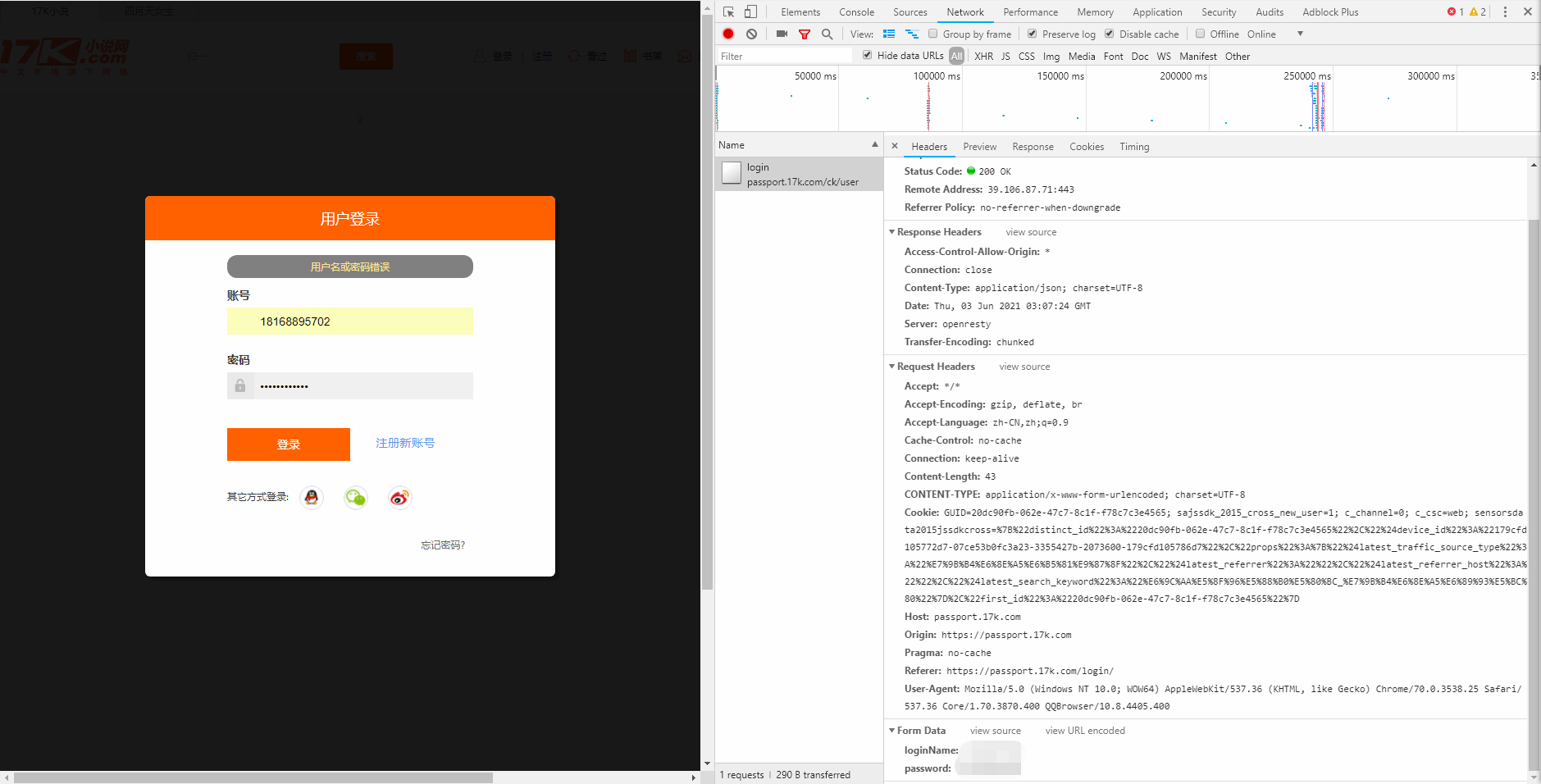
模拟浏览器登录
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| import requests
session = requests.session()
data = {
"loginName": "loginName",
"password": "password"
}
url = "https://passport.17k.com/ck/user/login"
resp_login = session.post(url=url, data=data)
print(resp_login.text)
print(resp_login.cookies)
resp_book = session.get("https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919")
print(resp_book.json())
resp_req = requests.get("https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919", headers={
"Cookie": "cookie"
})
print(resp_req.json())
|
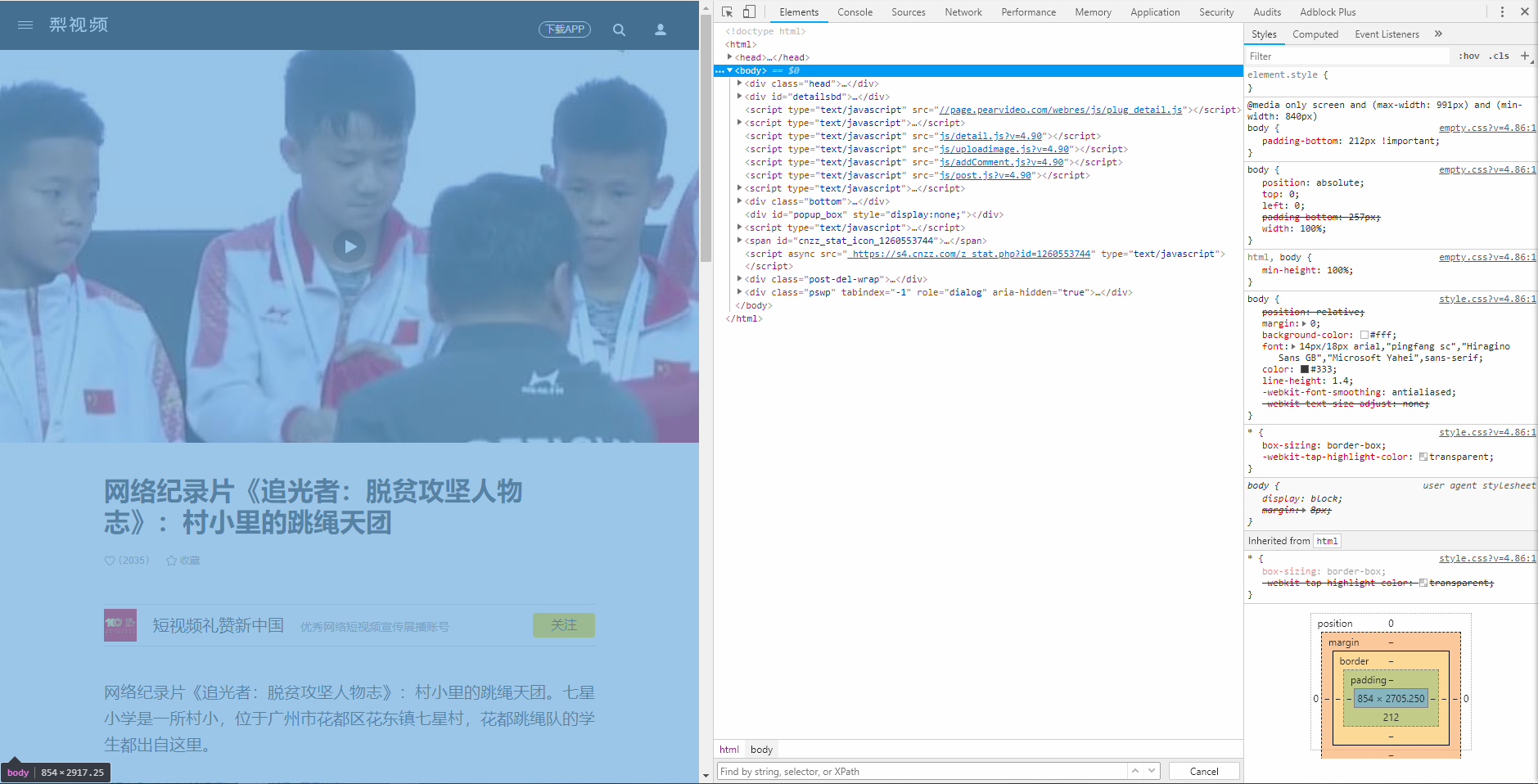
防盗链处理
- 虽然在开发者工具中能看到
- 服务器返回页面源代码之后生成以下右边的文件,之后的操作与页面源代码就没有关系了。
- 浏览器的视图界面是由右边的文件实时渲染的。当删除右边的语句时,左边的相应组件也会同步消失。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| import requests
url = "https://www.pearvideo.com/video_1713901"
contId = url.split("_")[1]
videoStatus_url = f"https://www.pearvideo.com/videoStatus.jsp?contId={contId}&mrd=0.8770894467476524"
headers = {
"User-Agent": "User-Agent",
"Referer": url
}
resp = requests.get(url=videoStatus_url, headers=headers)
dic = resp.json()
system_time = dic["systemTime"]
video_url = dic["videoInfo"]["videos"]["srcUrl"].replace(system_time, f"cont-{contId}")
print(video_url)
with open(f"{contId}.mp4", mode="wb") as f:
f.write(requests.get(video_url).content)
|
代理
1
2
3
4
5
6
7
8
9
10
11
| import requests
headers = {
"User-Agent": "User-Agent"
}
proxies = {
"https": "115.219.2.82:3256"
}
resp = requests.get("https://www.baidu.com", headers=headers, proxies=proxies)
resp.encoding = "utf-8"
print(resp.text)
|
网易云音乐评论
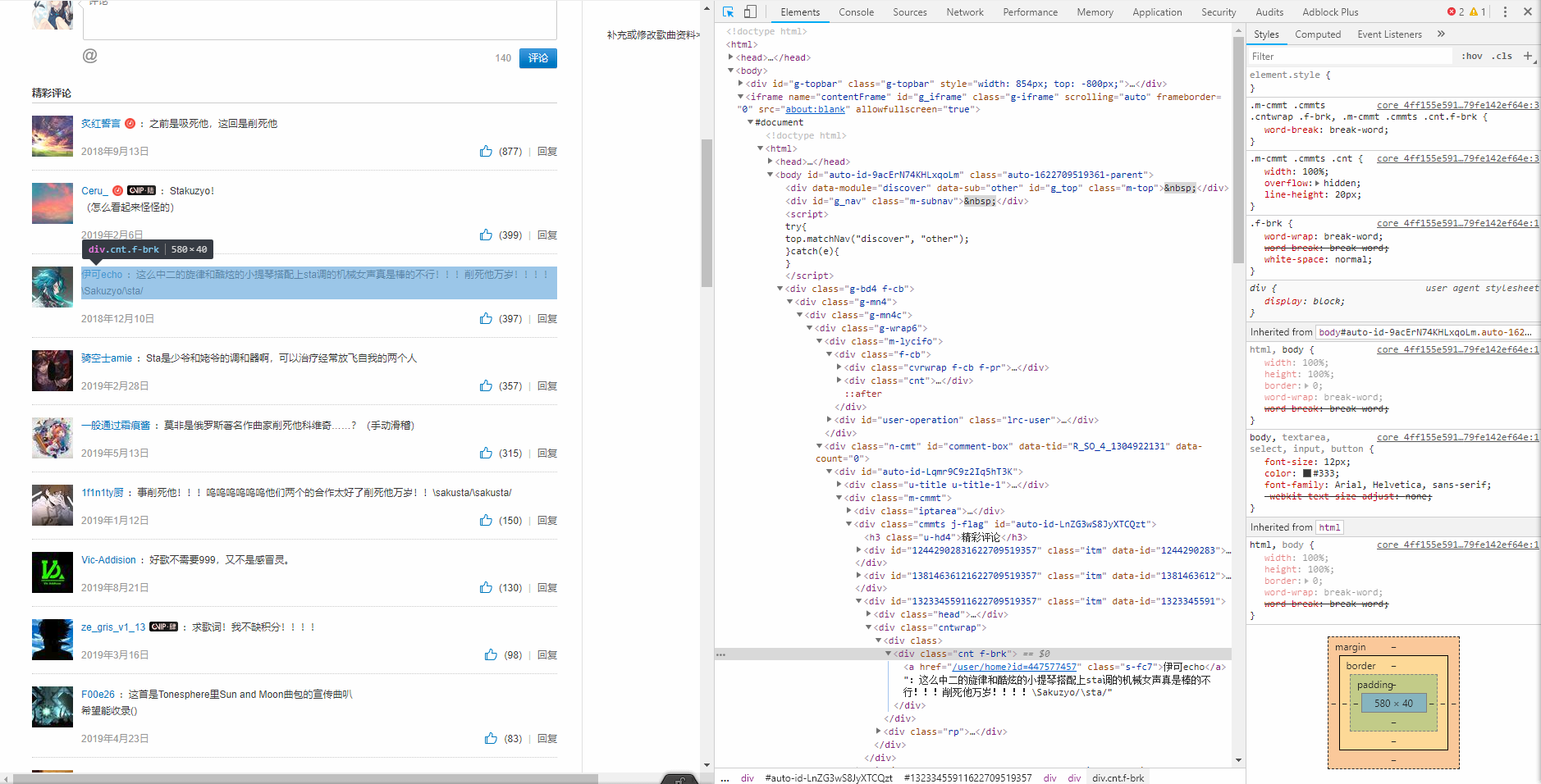
- 使用定位工具可以发现评论在html文件中的位置,但是不要忘了这是经过脚本生成的,并不是通过get使服务器返还的初始的网页源代码。
- 网易云音乐的网页页面是由多个html拼接而成,因此可以看见有框架源代码和网页源代码两个html文件。
- 但是在两个html中搜寻,均没有评论资源。由此可知,评论是通过二次请求得到的。
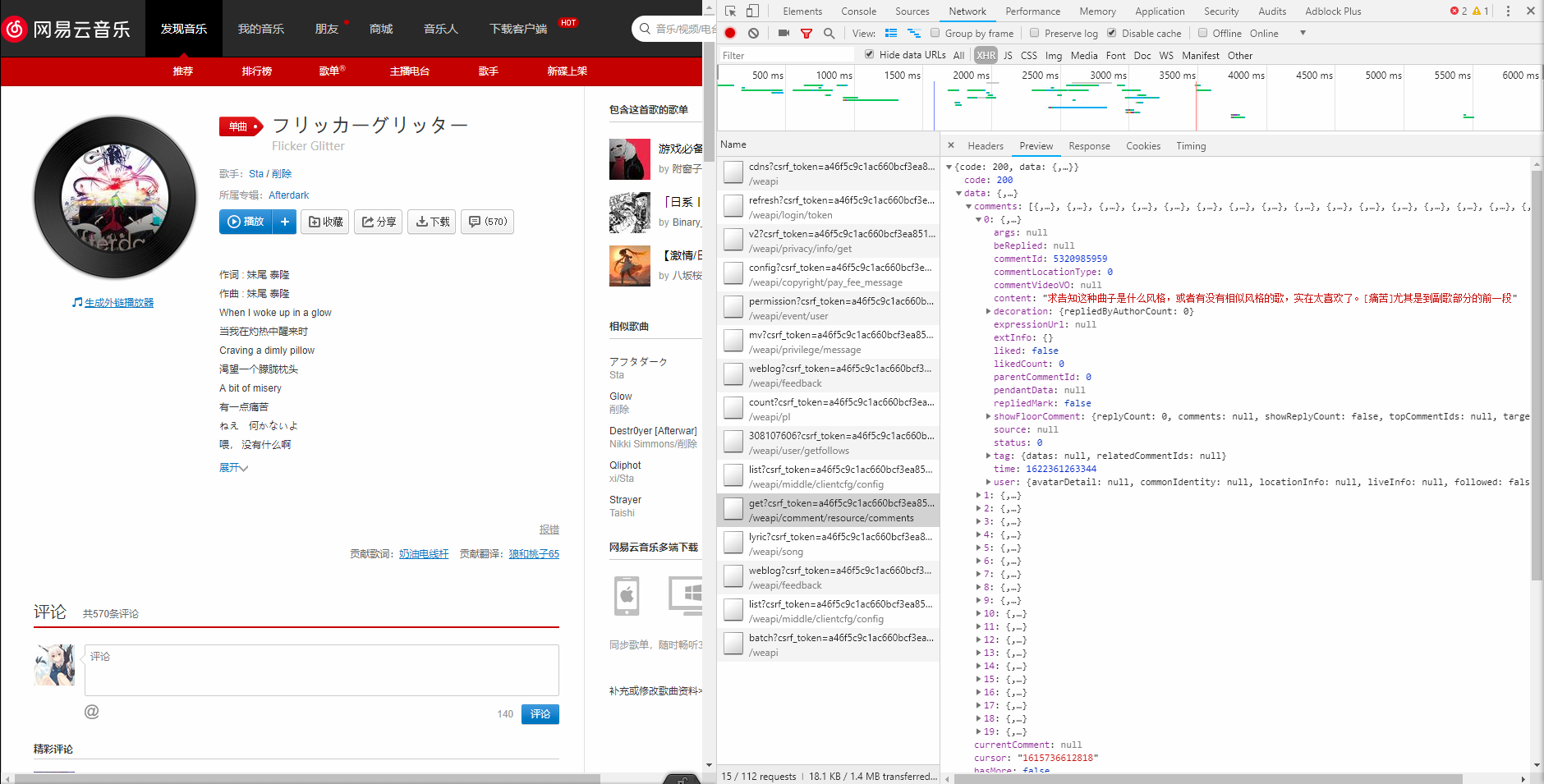
- 使用Network抓包工具->筛选XHR二次请求->找到comment资源
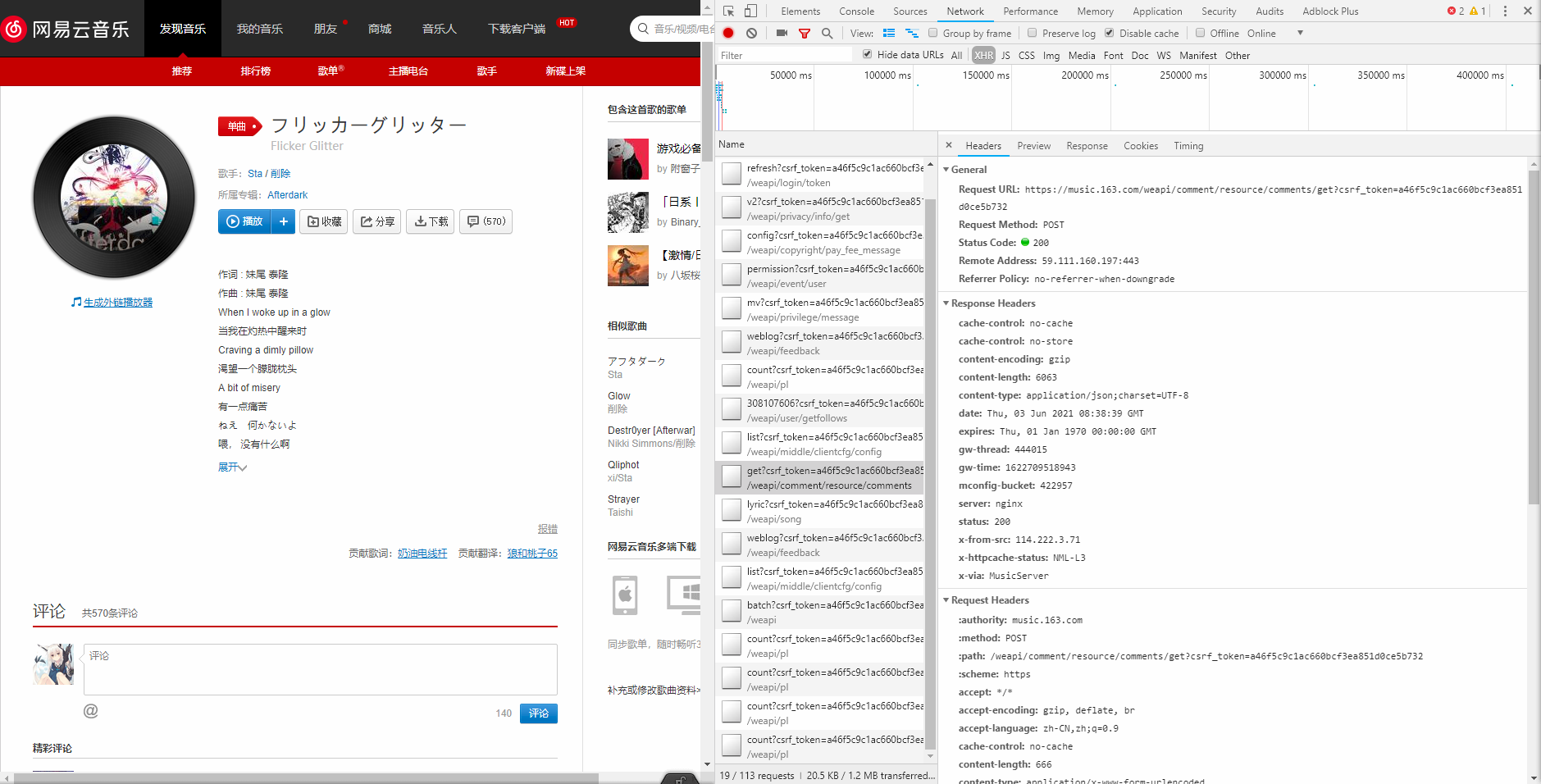
- 继续查看headers信息。可知:
- 请求目标的URL:
https://music.163.com/weapi/comment/resource/comments/get
csrf_token=后为登录信息,?后的参数可以忽略Request Method: POST请求方式为POST。- 同时发送了两个加密data:
params和encSecKey
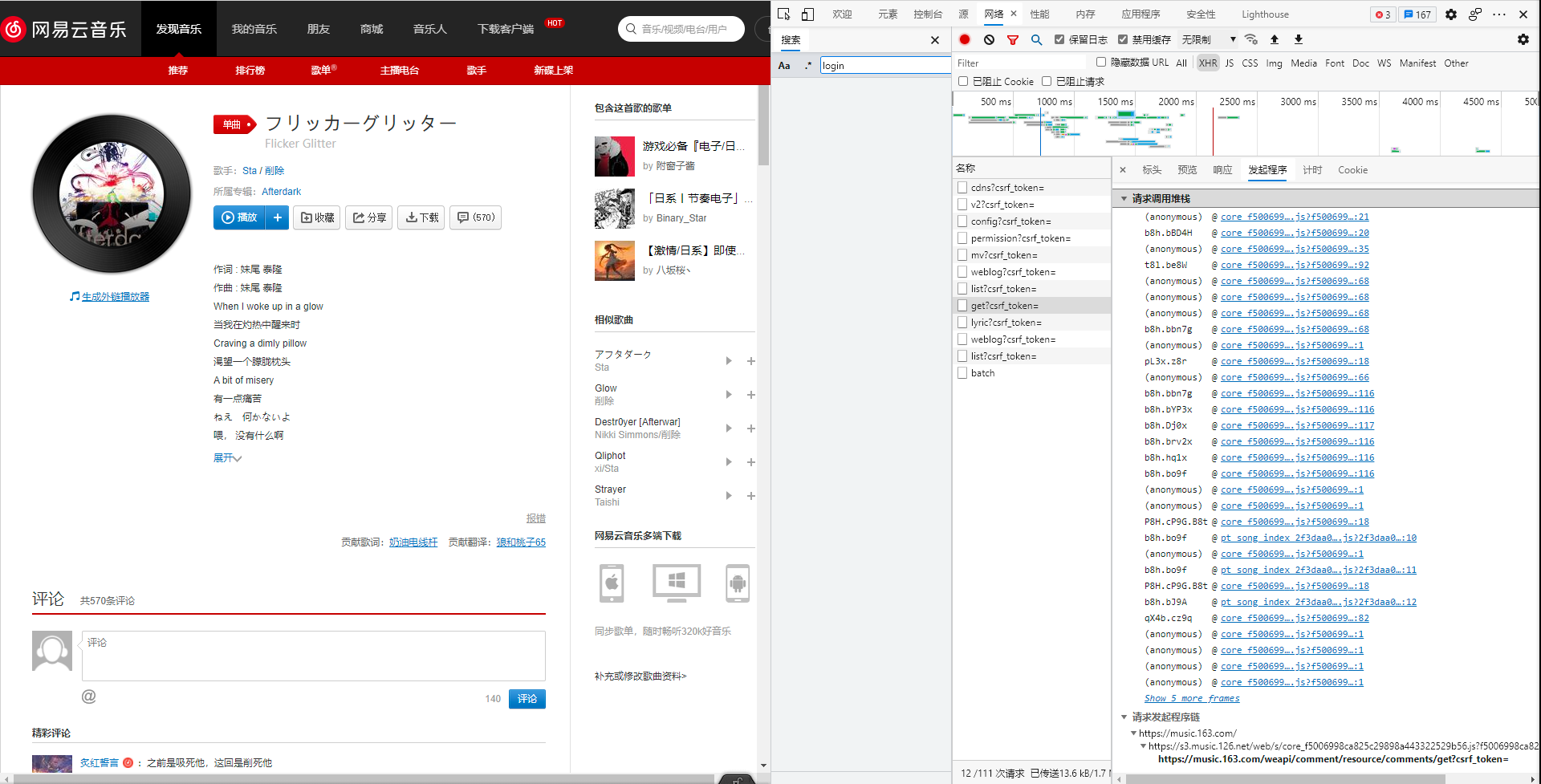
- 查看发起请求之前所调用过的栈、js脚本执行的过程。最开始执行的在最底部。点击最后调用的脚本。
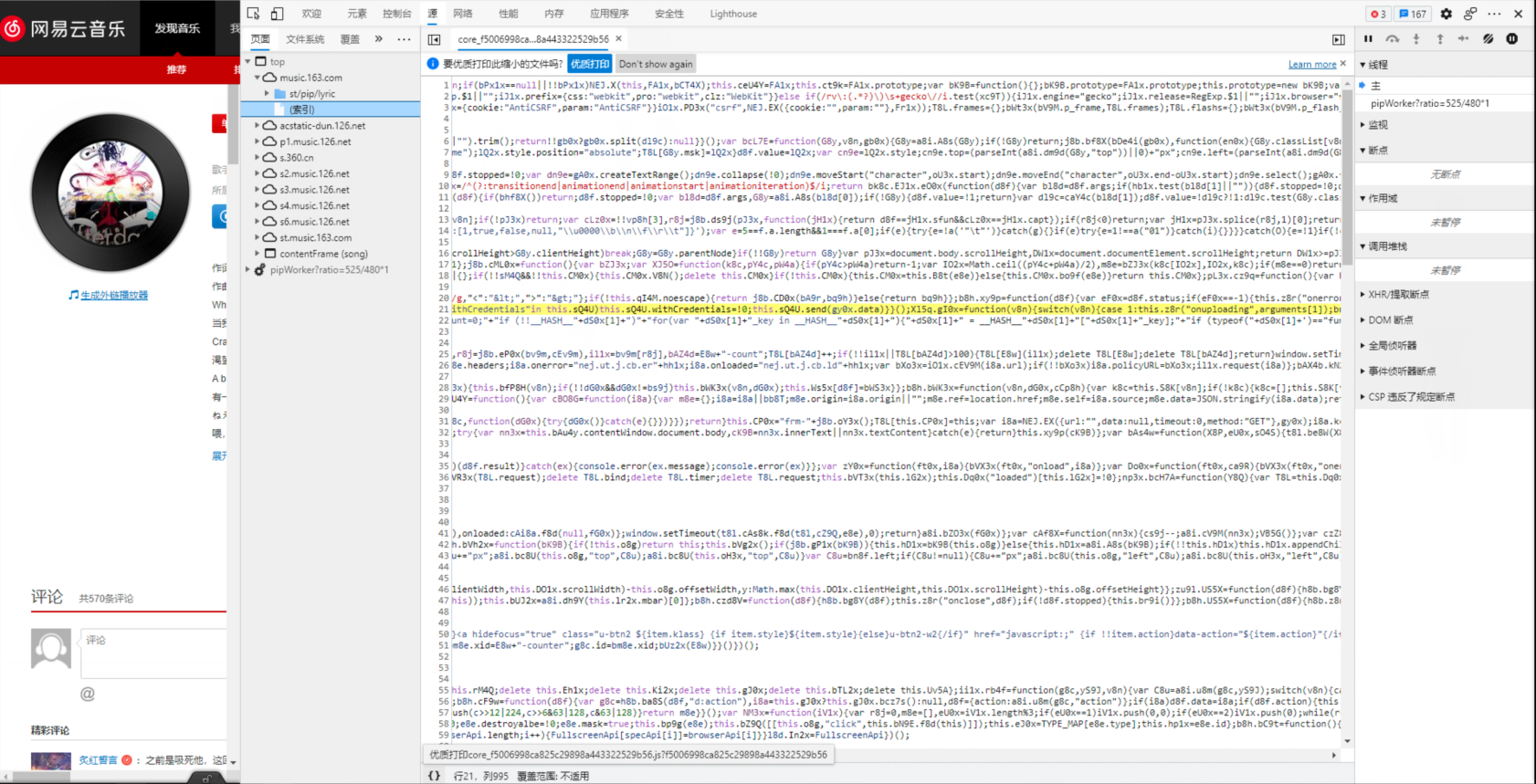
- 现在是压缩过后的代码,需要点击正下方的按钮,更换成优质打印。
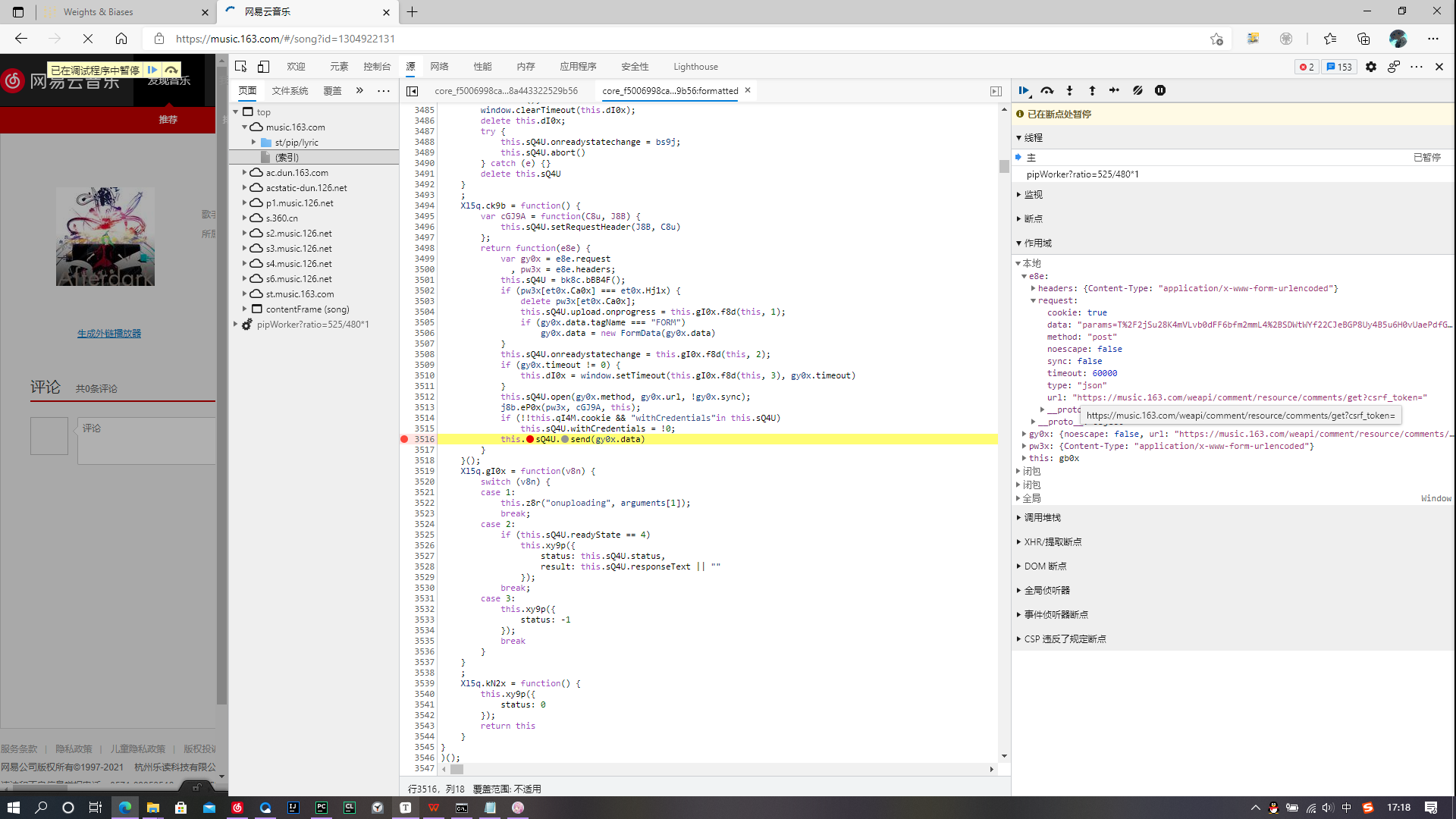
- 在语句
send()处设置断点,刷新网页
- 观察变量
request->url,恢复程序执行直到更新为https://music.163.com/weapi/comment/resource/comments/get
- 数据处于加密状态,因此需要通过调用堆栈不断回调函数,直到找到未加密的data
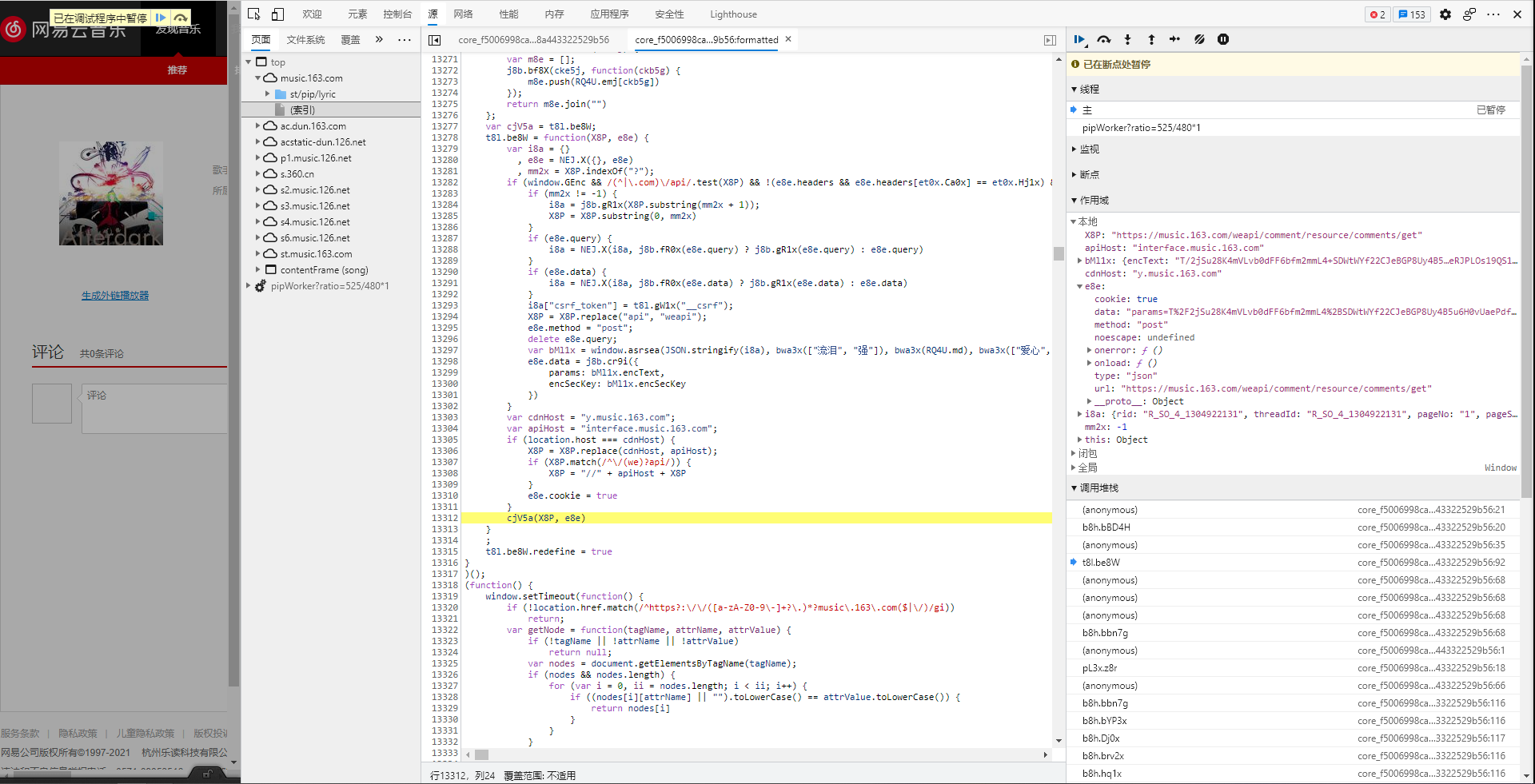
- 回调时发现data未加密,立刻定位到加密函数为
t8l.be8W
- 数据在变量
i8a与变量e8e之间完成了加密
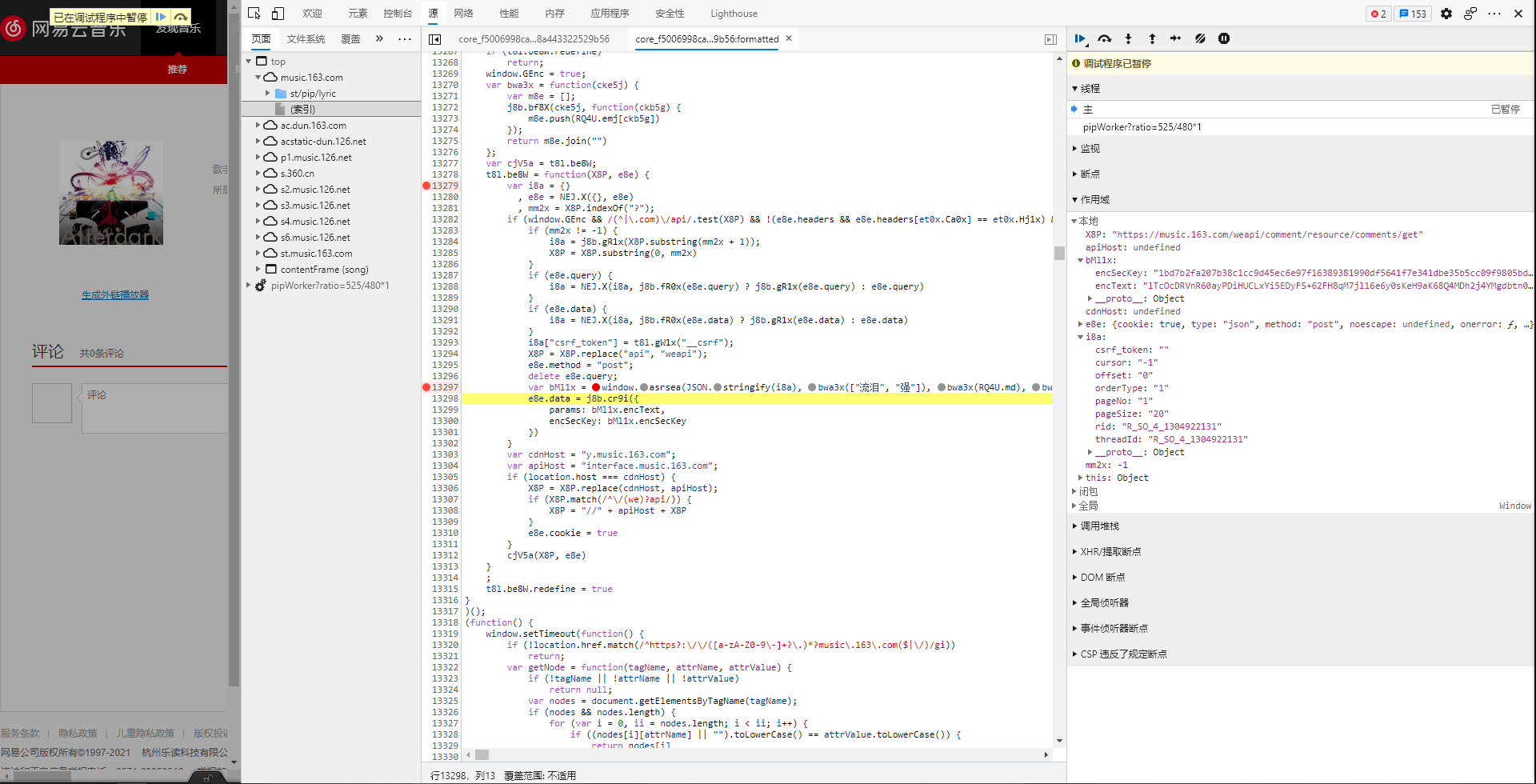
- 需要在已定的小范围内进一步缩小范围,因此在函数开始处增加新断点,重新刷新页面
- 发现在
window.asrsea()方法中i8a作为参数之一,返回变量bMl1x
- 发现变量
bMl1x已经被加密,拥有encSecKey和encText
bMl1x的数据又赋给e8e.data,由此加密data完成
简易实现版
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| import requests
api = "https://music.163.com/api/comment/resource/comments/get"
data = {
"cursor": "-1",
"offset": "0",
"orderType": "1",
"pageNo": "1",
"pageSize": "20",
"rid": "R_SO_4_1841819403",
"threadId": "R_SO_4_1841819403"
}
resp = requests.get(api, params=data)
json = resp.json()
print(resp.json())
|