爬虫Part1
爬虫Part1——原理与request入门
[TOC]
基本知识
爬虫:模拟浏览器抓取网站资源。
爬⾍在法律上是不被禁⽌的,但是也具有违法⻛险。因此使用爬虫我们要做到:
- 不能影响⽹站的正常运营
- 不能窃取⽤户隐私和商业机密等敏感内容
- 遵循 robots.txt 协议
第一个爬虫
1 | from urllib.request import urlopen |
- 在win10中必须加上 utf-8,否则使用环境默认值 gbk
- 网页本质就是html文件
- 在网页源码中有标记解码方式
使用edge要在 官网 下载对应版本的driver,pycharm中用浏览器打开地址都使用driver:
driver放在python根目录下:D:\Programming Kits\Python36\msedgedriver.exe
edge默认在:C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe
Web请求过程解析
网页上所有的数据不一定全在页面源代码中,这关系到常⻅的两种⻚⾯渲染过程:
服务器渲染
在请求到服务器的时候,服务器直接把数据全部写入到html中,因此我们能直接拿到带有数据的html内容,我们能看到的数据都在页面源代码中能找的到。
前端JS渲染
这种机制⼀般是第⼀次请求服务器返回基本的HTML框架结构,然后再次请求到数据库服务器,由这个服务器返回数据,最后在浏览器上对数据进⾏加载。
这便对应异步请求,在我们进行页面滚动时,浏览器向服务器发送数据请求。
这样做的好处是服务器缓解压力,而且分工明确,容易维护。
两种渲染对于爬虫都各有利弊。
Http协议
协议:就是两个计算机之间为了能够流畅的进⾏沟通⽽设置的⼀个协定。常⻅的协议有TCP/IP、SOAP协议、HTTP协议、SMTP协议等等…..
- HTTP协议,超⽂本传输协议(Hyper Text Transfer Protocol)的缩写,是⽤于从万维⽹(WWW:World Wide Web)服务器传输超⽂本到本地浏览器的传送协议。
- HTTP协议把⼀条消息分为三⼤块内容。
请求:
- 请求行 -> 请求方式(method:get/post)、请求地址(authority:url)、协议(scheme:https)、浏览器接受数据的要求(accept:)
- 请求头 -> 服务器要使用的附加信息(cookie),设备和浏览器信息(user-agent:)
- 请求体 -> 请求参数
响应:
- 状态⾏ -> 协议、状态码(200请求成功/404页面不存在/500服务器崩溃/302重定向)
- 响应头 -> 客户端要使⽤的附加信息
- 响应体 -> 服务器返回客户端真正要⽤的内容(HTML、json等)
写爬⾍的时候要格外注意请求头和响应头,这两个地⽅⼀般都隐含着⼀些⽐较重要的内容。
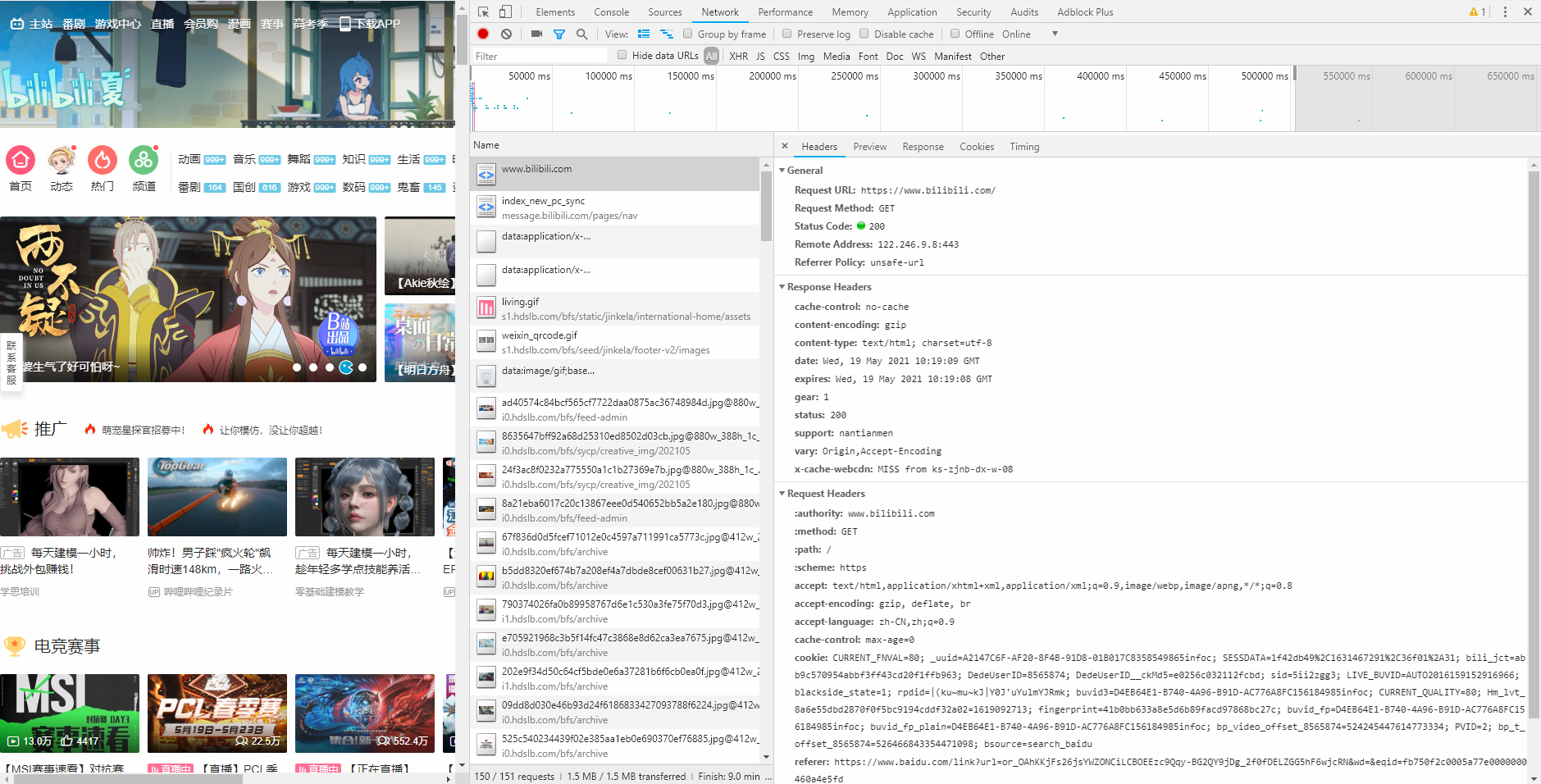
请求头中最常⻅的⼀些重要内容(爬⾍需要):
User-Agent:请求载体的身份标识(用啥发送的请求)
Referer:防盗链(这次请求是从哪个页面来的,反爬会⽤到)
cookie:本地字符串数据信息(用户登录信息,反爬的token)
响应头中⼀些重要的内容:
cookie
各种神奇的莫名其妙的字符串(⼀般都是token字样, 防止各种攻击和反爬)
请求⽅式:
- GET:显式提交。主要从服务器获取数据
- POST:隐式提交。主要向服务器传送数据
如果请求的方式是get或head,则只发送消息头到服务器;如果是post请求,那么消息体(网页表单内容)和消息头都将传送到服务器。因此,用get速度更快,但由于url暴露在用户面前,可能导致sql注入等非法攻击; 用post提交,速度会慢一些,但是由于url是隐藏在了表单中,所以安全性会好一点。这就是为什么,一般登录页面都用post提交而不用get提交。
request入门
GET显式提交
1 | import requests |
- 地址栏链接统一都是GET方式
POST隐式提交
1 | import requests |
- 对于像翻译这种发送请求才能接收数据的使用post,并且要注意请求的url。
- 一般第二次请求都是Type:xhr
带参数的get请求
1 | import requests |
- url地址的 ‘?’ 后面是get请求的参数(query string parameter)
- python模拟的user-agent为:python-requests/2.25.1
- 一般出现问题,首先检查headers的user-agent