PyTorch深度学习实践Part7——处理多维特征的输入
多维特征输入
从单一特征的数据,转而输入多为特征的数据,模型发生以下改变:
对于每一条(/第i条)有n个特征(x1…xn)的数据,则有n个不同的weight(w1…wn)和1个相同的bias(b将进行广播),并通过非线性激活函数,得出一个y_hat(假设输出维度为1)。
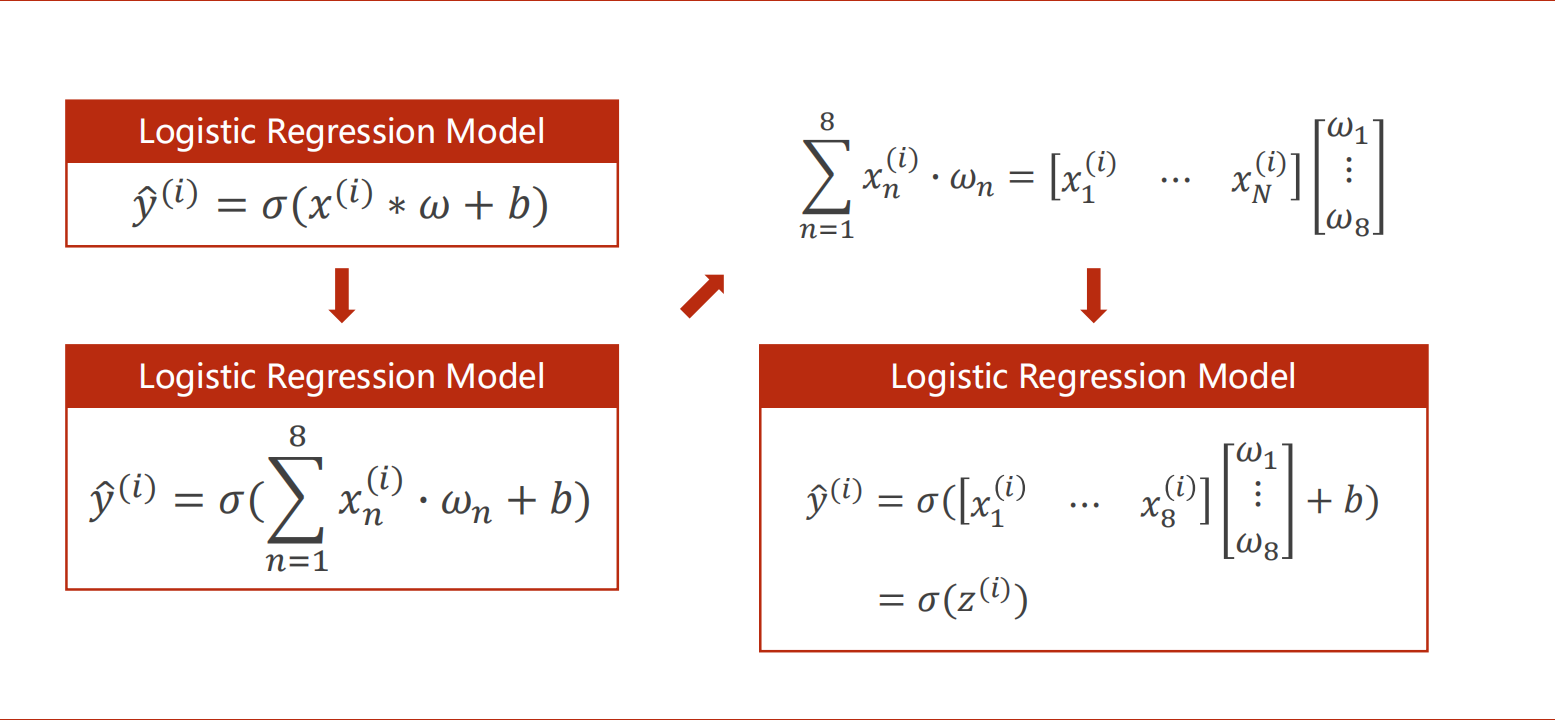
对于每个zn(=xn*wn+b)都要通过非线性激活函数,Sigmoid函数是对于每个元素的,类似于numpy。
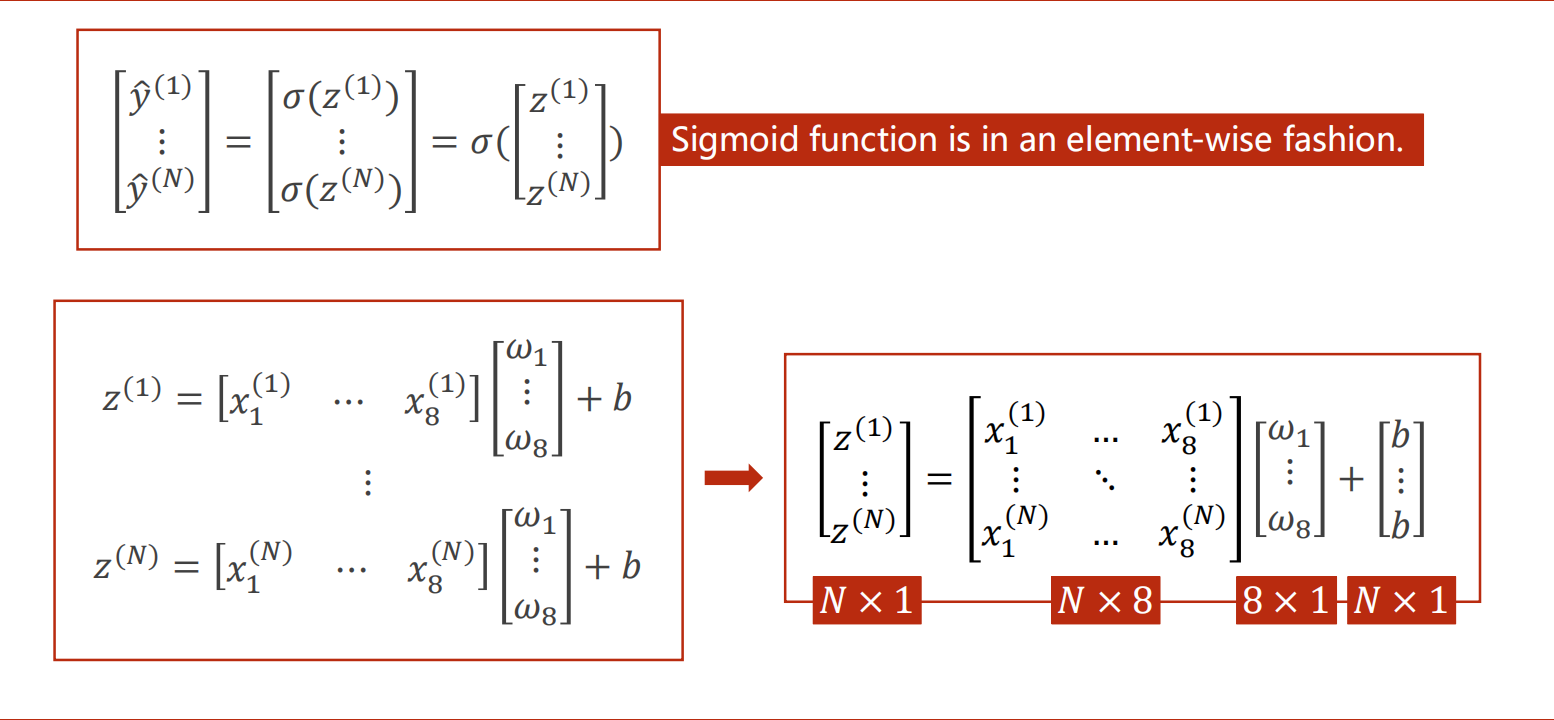
转换成矩阵运算可以发挥cpu/gpu并行运算的优势。
在之前的代码上,想要进行多维输入,只需要修改样本以及模型构造函数。
增加神经网络层数
- 如何增加神经网络层数?将多层模型输入和输出,头尾相连。例如:torch.nn.Linear(8, 6)、torch.nn.Linear(6, 4)、torch.nn.Linear(4, 1)。
- 什么是矩阵?矩阵是空间变换函数。例如:y=A*x,y是M×1的矩阵,x是N×1的矩阵,A是M×N的矩阵,则A就是将x从N维转换到y这个M维空间的空间变换函数。
- 矩阵是线性变换,但是很多实际情况都是复杂、非线性的。所以,需要用多个线性变换层,通过找到最优的权重组合起来,来模拟非线性的变换。寻找非线性变换函数,就是神经网络的本质。
- 多层神经网络可以降维也可以升维,至于如何达到最优,则是超参数的搜索。
- 神经元、网络层数越多,学习能力就越强,但是同时要小心过拟合的问题。要学习数据真值和具备泛化的能力。

能在编程道路上立稳脚跟的核心能力:
- 读文档
- 基本架构理念(cpu、操作系统、主机、编译原理)
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| import torch
import numpy as np
import matplotlib.pyplot as plt
xy = np.loadtxt('diabetes.csv.gz', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1])
y_data = torch.from_numpy(xy[:, [-1]])
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.activate = torch.nn.Sigmoid()
def forward(self, x):
x = self.activate(self.linear1(x))
x = self.activate(self.linear2(x))
x = self.activate(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=1.0)
loss_list = []
for epoch in range(500000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
loss_list.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
plt.plot(range(500000), loss_list)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
layer1_weight = model.linear1.weight.data
layer1_bias = model.linear1.bias.data
print("layer1_weight", layer1_weight)
print("layer1_weight.shape", layer1_weight.shape)
print("layer1_bias", layer1_bias)
print("layer1_bias.shape", layer1_bias.shape)
|
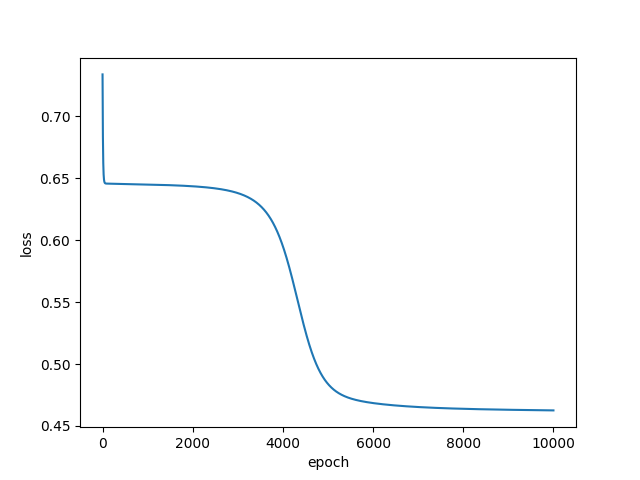
- 在100次训练时,损失卡在了0.65。
- 在1w次训练时,损失跨过0.65停在了0.45。
- 将学习率提升到10.0,1w次训练可以看出图像震荡,无法收敛,但是损失突破0.4以下。
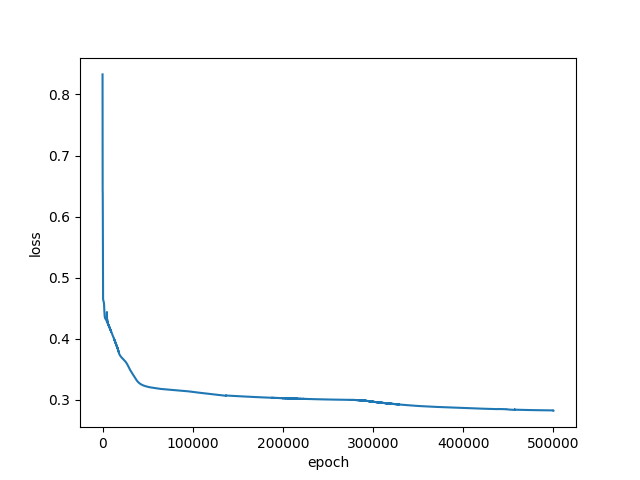
- 将学习率调整到1.0,10w次训练,损失突破0.3以下
- 学习率1.0,50w次训练,损失达到0.28
- pytorch激活函数文档