PyTorch深度学习实践Part12——循环神经网络(基础篇)
循环神经网络RNN
之前一开始用的是稠密网络DNN,因为是全连接,所以对每个元素都有相应的权重,因此其计算量是远大于看似复杂但是具有权重共享特性的CNN的。而RNN就是延续权重共享理念的网络。
RNN主要处理有序列连接的数据,比如自然语言、天气、股市、视频等。
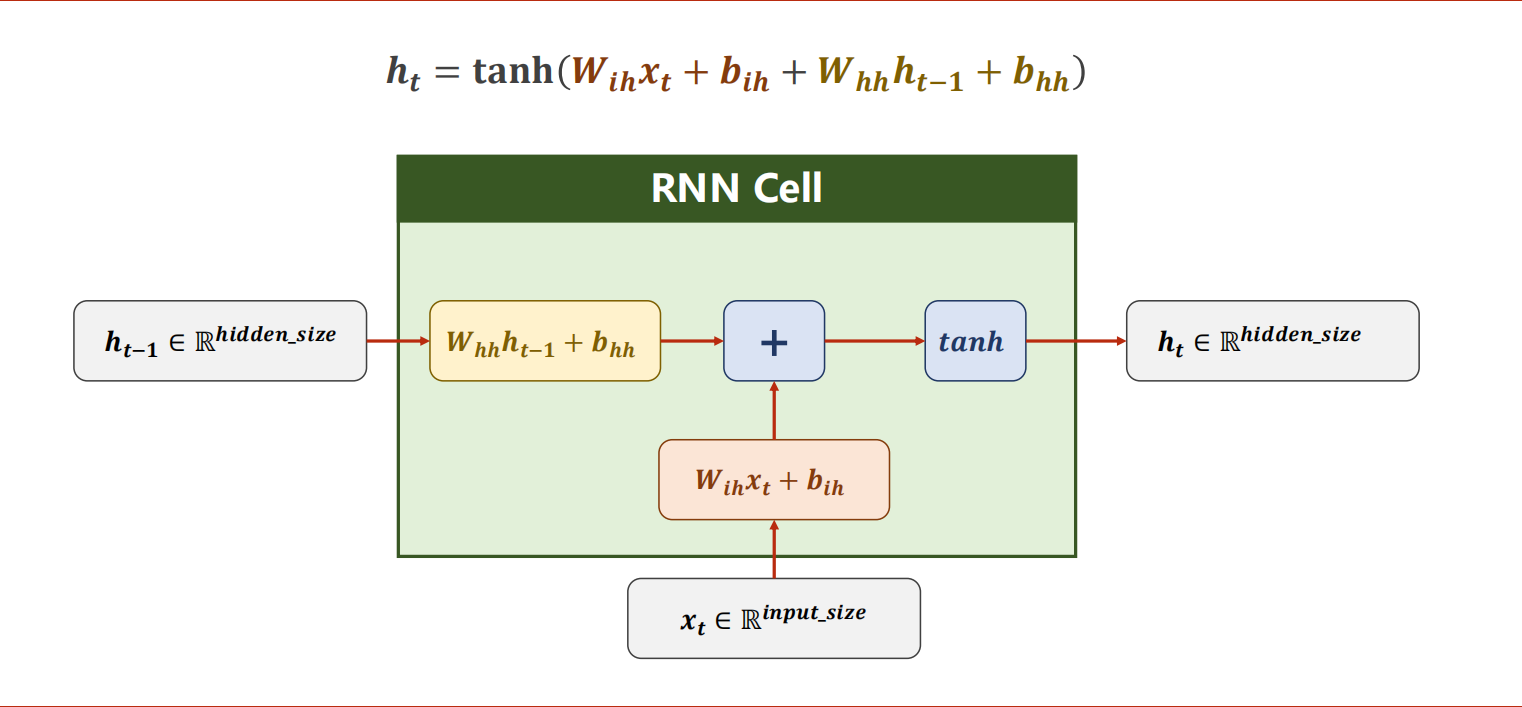
RNN本质是一个线性层,与DNN不同是RNN Cell是共享的。
从图像到文本的转换:CNN+FC+RNN。
循环神经网络的激活函数更常用tanh。
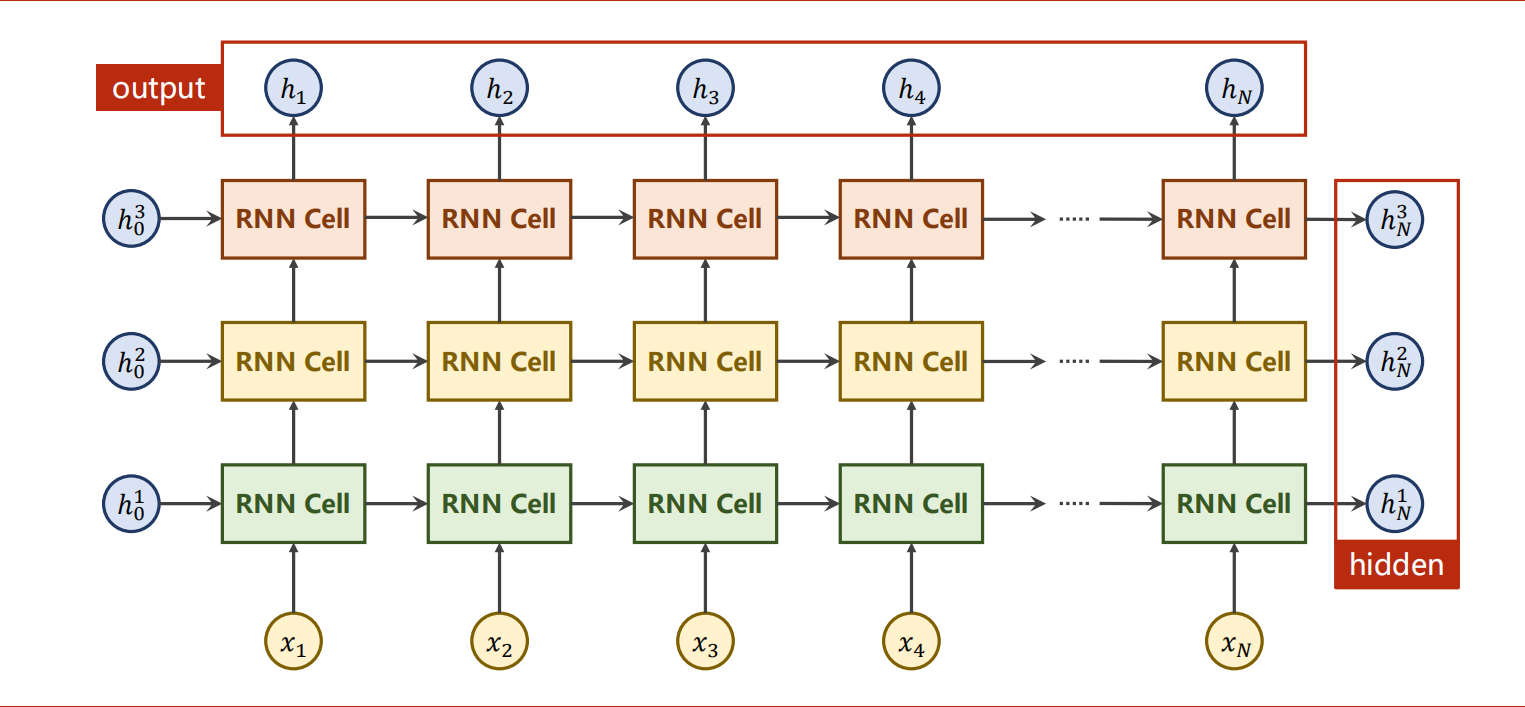
可以选择使用RNN Cell自己构建循环,也可以使用RNN。
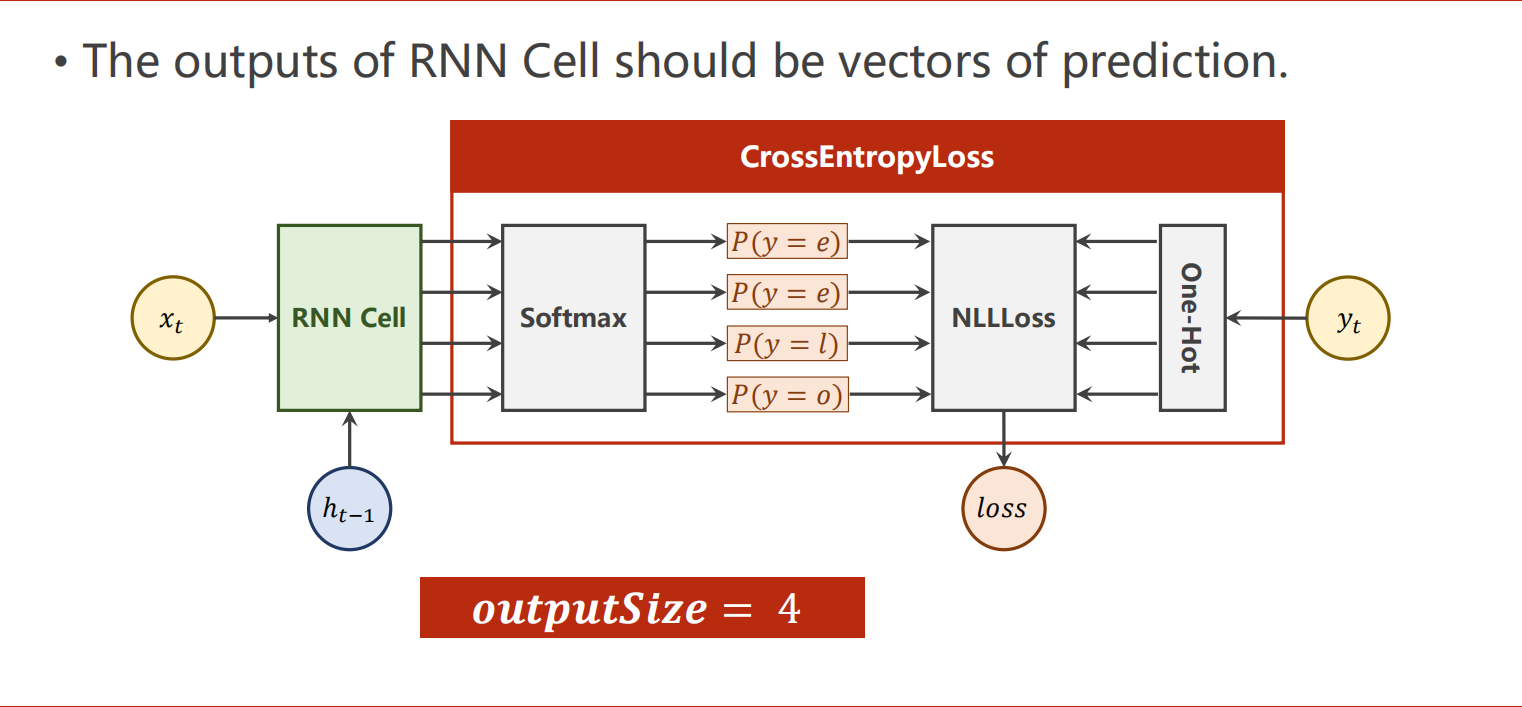
独热编码
处理文本使用独热编码

嵌入层
独热编码的缺点:
- 维度高
- 稀疏
- 硬编码

使用Embedding改善优化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
| import torch
import torch.optim as optim
num_class = 4
input_size = 4
hidden_size = 8
embedding_size = 10
num_layers = 2
batch_size = 1
seq_len = 5
idx2char = ['e', 'h', 'l', 'o']
x_data = [[1, 0, 2, 2, 3]]
y_data = [3, 1, 2, 3, 2]
inputs = torch.LongTensor(x_data)
labels = torch.LongTensor(y_data)
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.emb = torch.nn.Embedding(input_size, embedding_size)
self.rnn = torch.nn.RNN(input_size=embedding_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True)
self.fc = torch.nn.Linear(hidden_size, num_class)
def forward(self, x):
hidden = torch.zeros(num_layers, x.size(0), hidden_size)
x = self.emb(
x)
x, _ = self.rnn(x, hidden)
x = self.fc(x)
return x.view(-1, num_class)
net = Model()
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.05)
def train(epoch):
for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print('Predicted: ', ''.join([idx2char[x] for x in idx]), end='')
print(', Epoch [%d/15] loss = %.3f' % (epoch + 1, loss.item()))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
|
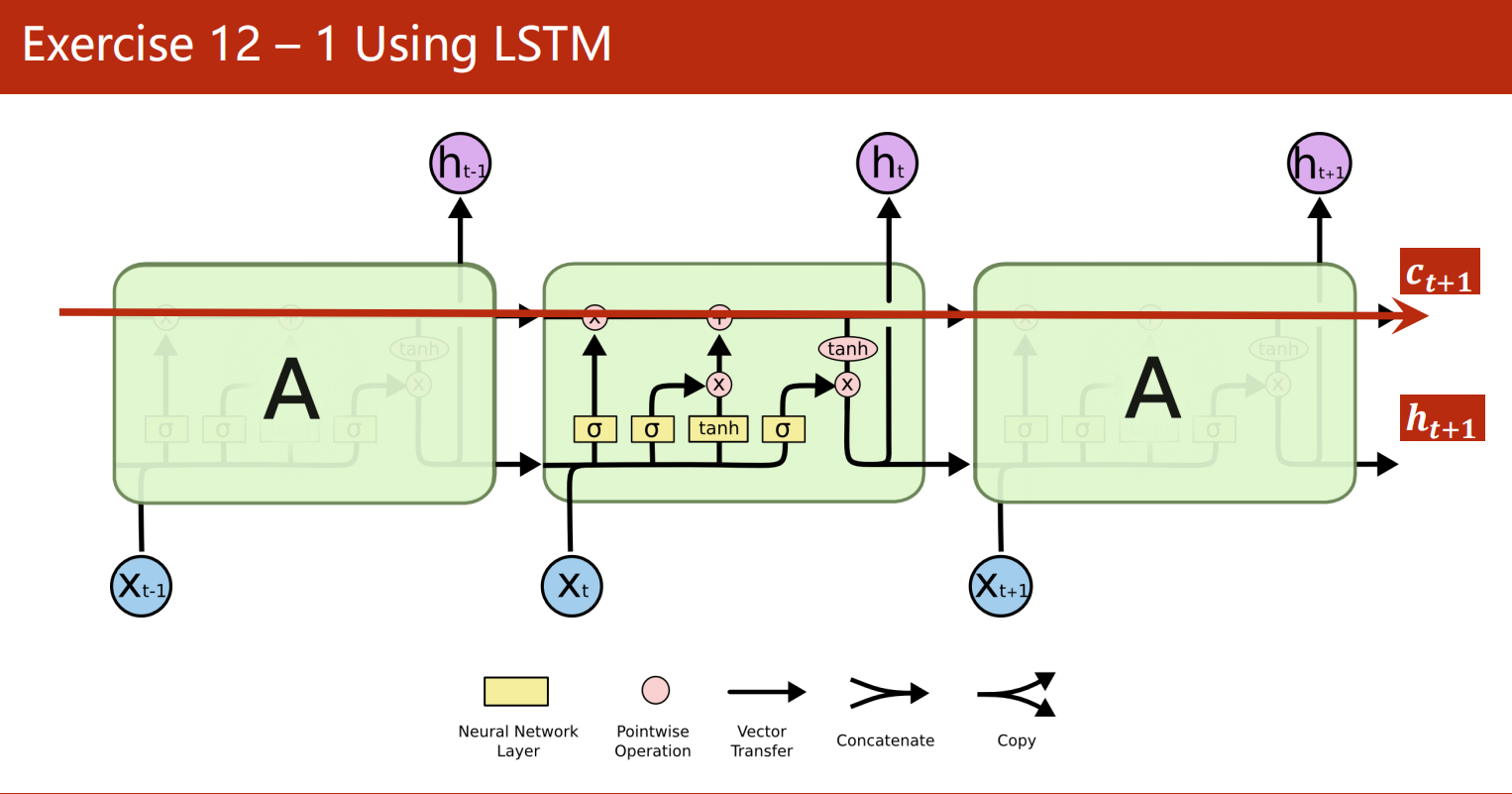
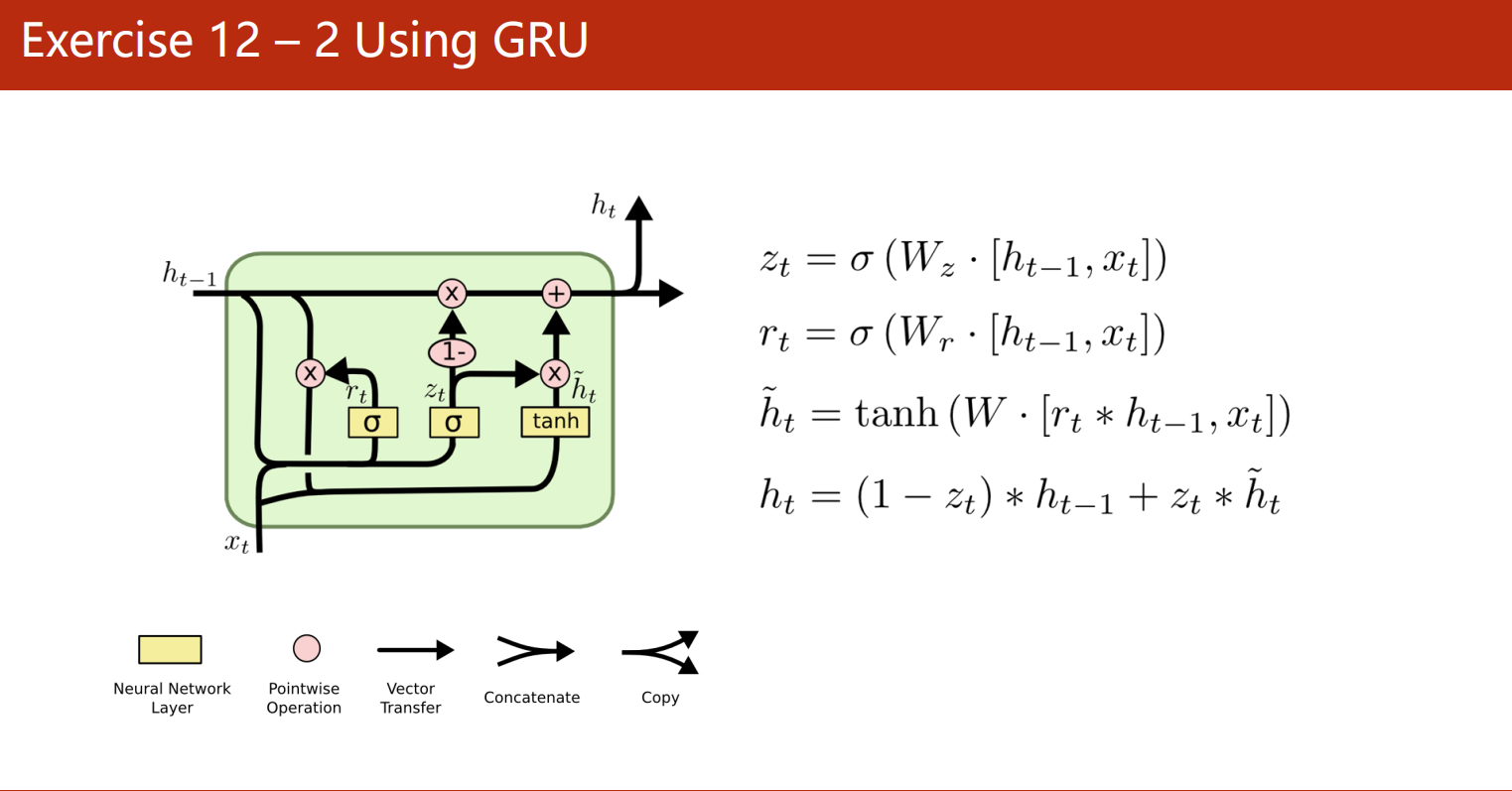
课后作业
使用LSTM和GRU训练模型